



什么是 AI 服务器?全球龙头AI 服务器公司以及ODM厂商?

目前一台配备8x GPU H100 / A100的AI服务器的价格在70–220 万人民币之间,一台入门级的2–4x 中端 GPUAI服务器价格也在15–45 万元之间。
2025 年全球 AI 服务器出货量持续增长,但受到一些供给侧因素(如部分 GPU 出货延迟)影响,增长略有调整。总体市场仍然呈现强劲上升态势,AI 服务器市场同比增长约 24% 左右。在 2025 年,全球大型云服务提供商(如 Google、AWS、Meta、Microsoft 等)预计将占据全球 AI 服务器采购数量的约 70%。 Google 母公司 Alphabet 表示2025 年计划用于数据中心与 AI 基础设施的资本支出约 750 亿美元左右。
大规模 CSPs 几乎主导了 AI 服务器市场的采购需求,这是因为他们不仅自建数据中心,还需要大量训练与推理算力。
▍AI 服务器与一般服务器究竟有什么不同?
AI 服务器与一般服务器最大的差异在于芯片构成。一般服务器主要以中央处理器(CPU)作为算力来源,而 AI 服务器除了 CPU 之外,还会搭载图形处理器(GPU)以及专用应用芯片(ASIC、FPGA、TPU 等),以应对 AI 运算所需的庞大算力需求。
简单来说,市场按类型可细分为:CPU+GPU、CPU+FPGA、CPU+ASIC以及其他的。
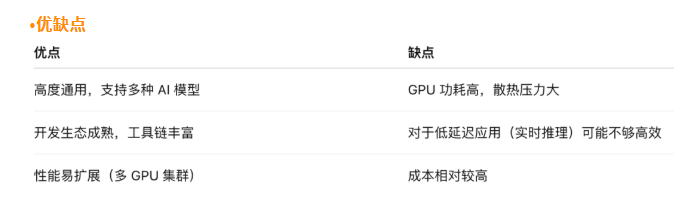
CPU + GPU 架构
☉ CPU(中央处理器)负责通用计算、控制任务和操作系统调度。
☉ GPU(图形处理器)负责高度并行的计算任务,擅长矩阵运算和向量处理。
☉ CPU 协调任务调度和数据传输,GPU 执行大规模并行计算(如深度学习中的卷积、矩阵乘法)。
·性能特点
☉ 并行能力强:GPU 内部有成百上千个计算核心,适合大规模数据并行处理。
☉ 浮点计算能力强,尤其适合深度学习训练(FP32/FP16/BF16)。
☉ 可灵活支持多种 AI 框架(TensorFlow、PyTorch 等)。
·适用场景
☉ 深度学习训练:模型训练、卷积神经网络(CNN)、Transformer 模型。
☉图形渲染与科学计算:3D 渲染、物理模拟。
☉ 高性能推理:GPU 也可用于推理任务,但功耗相对较高。
CPU + FPGA 架构
CPU 负责通用控制逻辑。
FPGA(现场可编程门阵列)是可编程硬件逻辑,可以根据需求自定义电路。
通过 FPGA 可将 AI 算法或加速单元“硬件化”,实现专用并行加速。
·性能特点
☉ 延迟低,实时性好:适合对响应时间敏感的推理任务。
☉ 功耗低于 GPU,能效比高。
☉ 可编程灵活,硬件可根据任务优化,但开发复杂。
·适用场景
☉ 边缘计算:工业 AI、IoT 设备。
☉ 推理加速:语音识别、图像分类、推荐系统。
☉ 定制化算法:需要在硬件级别优化的特殊算法。

CPU + ASIC 架构
☉ CPU 同样负责通用任务。
☉ ASIC(专用集成电路)为特定计算任务设计的芯片,硬件级优化。
☉ AI ASIC 如 Google TPU、比特大陆的 AI 芯片,专门为深度学习训练或推理定制。
·性能特点
☉ 极高计算效率和吞吐量,专为 AI 算法优化。
☉ 功耗最低,能效比高。
☉ 硬件固定,灵活性差,主要针对某类模型或算法。
·适用场景
☉ 大规模训练:Google TPU 用于训练大型深度学习模型。
☉ 云端 AI 推理:数据中心的高效推理服务。
☉ 量化推理:ASIC 可以做低精度量化计算,功耗更低。

▍市场机遇
人工智能工作负载优化成为关键市场驱动因素
2025 年全球服务器市场规模预计将达到约3660亿美元,同比增长约 44.6%。2025 年全球 AI 服务器市场规模约为 2450 亿美元,占当年整体服务器市场的大比例(约 70% 以上)。这种爆炸式增长源于企业通过专用硬件优化人工智能工作负载,这些硬件将传统CPU与GPU和ASIC等先进处理单元相结合。液冷技术的最新进展使得在保持散热效率的同时,能够实现更高密度的服务器配置,从而解决了高性能人工智能计算环境中的一项关键挑战。
GPU 和加速器技术的突破
现代 AI 工作负载需要传统 CPU 无法高效提供的处理能力。最新的 GPU 架构相比前几代产品,在 AI 训练方面性能提升了 10-15 倍,同时功耗更低。这种性能飞跃使得 GPU 加速服务器成为 AI 应用不可或缺的组成部分。此外,TPU 和 FPGA 等新兴加速器技术也正迅速发展,其采用率以每年 35% 的速度增长。这些技术进步使企业能够运行更复杂的 AI 模型,同时优化功耗和总体拥有成本。
边缘人工智能计算扩展
边缘人工智能计算的快速普及正在显著改变服务器需求,对能够进行实时处理的分布式计算架构的需求日益增长。企业正在部署混合人工智能服务器解决方案,以平衡基于云的训练和基于边缘的推理,尤其是在电信和工业物联网等对延迟要求极高的领域。这种转变正在推动服务器外形尺寸和能效方面的创新,一些市场领导者推出了机架优化配置,与传统数据中心服务器相比,每瓦性能提升高达 40%。
专用人工智能芯片集成重塑服务器架构
专用人工智能加速器的集成正在从根本上改变服务器设计范式。虽然GPU加速服务器目前占据主导地位,市场份额超过60%,但采用FPGA和ASIC解决方案的新架构在自然语言处理和计算机视觉等特定工作负载方面正逐渐获得青睐。主流云服务提供商越来越多地采用为其专有算法量身定制的AI芯片,从而推动了对能够容纳各种处理单元的模块化服务器设计的需求。这一趋势在为新市场参与者创造机遇的同时,也对传统服务器制造商提出了挑战,要求其调整产品线。
▍全球主要的AI 服务器公司及布局
不同用途(训练 vs 推理 vs 边缘 AI)对应厂商核心产品线对比表:

NVIDIA 是全球 AI 计算的核心供应商,尤其在 GPU 加速计算上几乎是事实标准。其 GPU 被广泛用于 AI 训练与推理服务器中。NVIDIA 推出 GB200、H200 等 AI GPU 核心组件,被大量集成到 Dell、HPE、Supermicro、浪潮、联想等服务器产品中;这些 GPU 可支持多达数百个核心/机架的训练任务。NVIDIA 还提供 企业级认证服务器系统(如 DGX 系列和合作 OEM 认证系统),为企业数据中心和研究机构提供端到端 AI 解决方案。
主要布局类型:
☉ AI 训练集群(超大规模 GPU 堆叠)
☉ OEM/ODM 服务器平台芯片供应
☉ 推理与边缘加速方案
△英伟达GB200
戴尔推出了基于 NVIDIA 芯片的 AI 服务器(例如支持最多192–256 Blackwell Ultra GPU 的机架服务器),可显著提升训练速度与吞吐量,符合大型企业和云服务客户需求。支持风冷与液冷等多种散热方案,适应不同数据中心配置。戴尔也在与云服务商合作,推动 AI 服务器部署(如为 xAI 等提供支持),同时其 PowerEdge 产品线越来越向 AI 推理和训练定制化方向发展。
主要布局类型:
☉ 大规模训练服务器(高密度 GPU 机架)
☉ 企业推理与边缘 AI 部署
☉ 定制化行业 AI 解决方案
HPE 在其 ProLiant 系列服务器中集成最新 NVIDIA GPU(如 RTX PRO 6000 Blackwell)以扩展 AI 能力,同时扩展 private cloud 和 hybrid cloud AI 服务。这些配置主要面向企业级 AI 推理、生成式 AI 工作负载以及虚拟化 AI 基础设施。HPE 的布局强调与云服务、数据中心和企业内部混合部署的灵活性。
主要布局类型:
☉ 企业与私有云 AI 服务器
☉ GPU 推理与训练混合场景
☉ 高性能计算与 AI 融合平台
浪潮在中国 AI 服务器市场占据领先地位,在国内份额长期保持最高(约55–60%),并与 NVIDIA 深度合作,涉足大型训练和推理服务器。常见产品例如 NF5488M6、NF5688M6 等,可以集成 NVIDIA GPU 和其他加速卡,面向云计算、大数据和 AI 训练部署。在全球市场也持续扩展,与阿里、腾讯等头部互联网企业合作,参与大型 AI 集群建设。
主要布局类型:
☉ 大规模训练与推理服务器
☉ 云服务商集群设备
☉ 国产方案与信创兼容产品
● 华为技术有限公司(中国)
华为提供自己的AI 服务器,支持搭载昇腾(Ascend)AI 加速器和第三方 GPU,为训练与推理提供端到端基础。华为布局强调与自家 AI 芯片生态(昇腾芯片及鲲鹏处理器)相结合,以减少对外部芯片依赖,并推动本土 AI 基础架构成长。
主要布局类型:
☉ 自研 AI 芯片训练/推理服务器
☉ 混合 GPU/昇腾加速混合平台
☉ 高性能企业级 AI 基础设施
△新一代昇腾AI推理服务器“超强A800I V7”
● IBM公司(美国)
IBM 发布了自家 Power11 芯片及服务器系统,重点提升 AI 推理与企业工作流自动化部署,而不直接与 NVIDIA 训练级产品竞争。IBM 的 AI 服务器强调能效、可靠性和集成式体验,适合金融、制造等行业的企业级 AI 负载。
主要布局类型:
☉ 企业级推理与优化系统
☉ 高可用性/低停机 AI 平台
☉ 垂直行业 AI 加速服务
联想的ThinkSystem AI 服务器系列可集成 GPU 与其他加速卡,适用于云/企业级 AI 部署。作为国内主要整机厂商之一,联想同时服务于云供应商、企业和科研机构。联想在国内参与多种大型采购项目,与 CPU/AI 加速器供应商合作布局。
主要布局类型:
☉ 多用途训练 & 推理服务器
☉ 混合加速与企业 AI 平台
☉ 信创与国产生态兼容产品
● 超微(美国)
Supermicro 在全球 AI 服务器市场非常活跃,特别是在高密度 GPU 配置、液冷部署和定制化方案上。Supermicro 常与 NVIDIA 合作推出针对大型训练集群的整体平台。公司在高性能密集型服务器领域具有优势,特别是面向科研、企业和云服务场景。
主要布局类型:
☉ 高密度训练服务器
☉ 定制化企业级解决方案
☉ 与云厂商联合部署
● 新华三(H3C)
新华三的 AI 服务器产品线覆盖高密度 GPU 训练服务器与行业推理节点,强调与网络、存储及数据中心架构的深度整合能力。依托其在政企与运营商市场的长期积累,新华三的 AI 服务器多用于政务云、行业大模型、城市算力中心等场景部署。
作为国内重要的企业级 ICT 基础设施厂商,新华三不仅提供 GPU 服务器硬件,还具备整机柜交付、液冷系统集成及数据中心整体方案能力。在国产化趋势推动下,其产品也逐步加强对鲲鹏、昇腾等国产芯片生态的适配。
主要布局类型:☉ 多卡高密度训练服务器
☉ 行业级推理与算力节点部署
☉ 信创与国产生态兼容产品
☉ 整机柜交付与数据中心整体解决方案
● 中科曙光(Sugon)
中科曙光的 AI 服务器体系延续其在高性能计算(HPC)领域的技术积累,重点布局大规模训练集群与科研级算力平台。其产品广泛应用于国家级算力中心、科研机构及政府主导的算力基础设施项目。
作为国内超算与算力工程的重要参与方,中科曙光在高性能互连、集群调度及液冷系统方面具有较强工程能力。近年来,公司在 NVIDIA GPU 平台与国产 CPU/AI 芯片体系上同步推进,强化对大规模 AI 训练场景的支撑能力。
主要布局类型:
☉ 大规模训练服务器与集群节点
☉ HPC + AI 融合算力平台☉ 国产 CPU/AI 芯片适配方案☉ 液冷与高密度算力基础设施部署

● 富士通(日本)
富士通提供高性能计算与 AI 服务器方案,通常用于科研机构、企业和对能效与可靠性有高要求的场景。虽然在全球市场份额不如上述巨头,但在日本和亚太部分区域保持稳定客户群。
主要布局类型:
☉ 高性能 AI / HPC 混合系统
☉ 企业 AI 与科研平台
● 思科系统(美国)
思科近期发布面向 AI 数据中心的新型网络芯片和路由器,旨在通过高效网络加速 AI 工作负载的数据传输,提升整体 AI 基础设施性能。虽然不是传统意义上的整机 AI 服务器厂商,但思科在网络层与数据中心整体架构层面的布局对高性能 AI 服务至关重要。
主要布局类型:
☉ 数据中心网络加速与 AI 网络硬件
☉ 与 AI 服务器协同优化整体架构

● 宝德(中国)
宝德在中国 AI 服务器市场中扮演着“本土大型项目供应商”的角色,尤其活跃于 电信运营商、政府采购及大型企业重点项目。其核心优势在于能够提供数量大、配套齐全的 AI 服务器交付方案,满足从训练到推理的多样化需求。
主要布局类型:
☉ 国产AI 服务器与系统整合
☉ 国家与行业重点项目
☉ 混合加速方案
● 神州数码(中国)等
神州数码则在中国 AI 服务器市场中以 国产化生态为切入点,尤其侧重于鲲鹏/昇腾体系的服务器产品线,服务对象多为中文云生态和国产化计算环境。
主要布局类型:
☉ 国产 CPU/GPU 加速器
☉ 中文云生态部署
☉ 国家与行业重点项目
▍全球核心 AI 服务器 ODM 厂商及布局
- 广达
- 纬颖
- 鸿海体系(富士康、工业富联等)
- 英业达
- 神达
- 和硕
- 仁宝等
根据《证券时报》指出,鸿海在全球 AI 服务器市场的市占率约为 40%,是目前的 AI 服务器龙头厂商。
服务器代工制造可分为多个不同阶段,从 L1 到 L12 分别代表不同制程环节。TrendForce 指出,这些制程阶段实际上反映了服务器代工厂的发展策略方向,大致可分为 L6 与 L10 以上两个主要层级。若代工厂专注于 L6 主板生产,通常会与系统整合商进行策略合作,例如英业达与近期出售给 AMD 的 ZT Systems(美国服务器系统整合商)。另一条路径则是直接提供 L10 整机,甚至延伸至 L12 整柜的完整解决方案。
⊙ L6 阶段——主板制造与组装:英业达具主导地位
L6 阶段主要涉及服务器主板的制造与基础组装,是服务器制造的核心基础环节。台湾厂商在该阶段具备显著优势,其中尤以英业达与广达最具代表性。英业达在 L6 阶段的市占率高达六成,是全球主要的 AI 服务器主板供应商之一。同时,英业达也积极向 L10 与 L11 阶段延伸,持续扩大其在 AI 服务器市场中的影响力。
广达在 L6 阶段同样拥有超过两成的市占率,近期也宣布考虑在泰国新建 L6 产线,并同步布局 L10、L11 及 L12 阶段。
⊙ L10 阶段——整机组装与系统测试:鸿海提供一条龙解决方案
进入 L10 阶段后,服务器将整合 CPU、内存、存储硬盘等关键组件,并进行全面系统测试。该阶段的核心价值在于确保服务器具备稳定运行能力,并能直接交付客户使用。
鸿海作为 NVIDIA 最重要的供应商之一,在 L10 至 L12 阶段提供从模组制造到整机交付的一站式解决方案,是目前少数具备完整垂直整合能力的代工厂商。
⊙ L11 与 L12 阶段——整机架设与软件整合:纬颖持续强化 L12 整机柜方案
L11 与 L12 是服务器制造流程中的最后关键阶段。L11 主要负责多台服务器的整合、机架安装与数据中心部署;L12 则进行最终的软件载入、系统优化与集群管理,确保服务器可在大型数据中心中稳定运行。
纬创与广达在 NVIDIA GPU 基板与服务器制造中扮演重要角色,并参与 L6、L10 等多个阶段;纬颖则聚焦于 L6 与 L12 阶段。纬颖表示,希望通过提供数据中心整体解决方案,进一步强化其在 AI 服务器供应链中的战略位置。
▍ASIC AI服务器的出货占比将超越GPU AI服务器
预计2026年全球Server出货年成长为12.8%,AI Server出货年增28%以上,2025年下半年起,AI Agents、LLaMA模型应用、Copilot升级等AI推理服务持续发展,CSP积极转向推理服务以发展变现及获利模式。基于不同应用场景,AI推理除了可采用AI Server机柜,亦包括通用型Server,以支撑推理前后的运算和存储需求。
根据TrendForce统计, Google、AWS(亚马逊云科技)、Meta、Microsoft、Oracle(甲骨文)等北美五大CSP 2026年的资本支出总额年增率高达40%,除了为布局大规模基础建设,也有部分是汰换2019至2021年云端投资热潮购置的通用型Server。预计Google和Microsoft将最积极提升通用型Server采购量,以应对每日需实体提供的Copilot、Gemini推理流量需求。
观察2026年AI Server市场,出货动能主要来自北美CSP、各地政府主权云项目,以及大型CSP加快自有ASIC研发、边缘AI推理方案的助力。从使用的AI芯片分析,预估GPU占69.7%,仍为最大宗;其中,搭载NVIDIA(英伟达) GB300的机种将成为出货主流,VR200则于下半年后逐步放量。
然而,在Google、Meta等北美业者积极扩张自研ASIC方案的情况下,预计2026年ASIC AI Server的出货占比将提升至27.8%,为2023年以来最高,出货增速也超越GPU AI Server。Google对自研ASIC的投资力道明显强于多数CSP,将成为ASIC市场领头羊,其TPU除了自用于Google Cloud Platform云端服务基础设施外,也积极对外销售于Anthropic等业者。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。