



如何构建第一个智能体?GLM4.7 实战教程(附 Python 代码)

一、智能体的核心能力
智能体主要由感知、思考、执行、交互四大能力组成:
1. 感知
智能体能够主动或被动地获取外部数据(非训练数据),包括:
主动感知:根据任务自动获取所需数据
被动感知:接收用户上传的数据
数据获取方式和类型多样,是智能体与单纯大语言模型的核心区别之一。
2. 思考
基于训练好的大语言模型作为基座,具备先验知识,能够:
根据已有知识对问题进行理解和分析;形成答案并进行推理
从人类视角看,这就是"思考能力"
3. 执行
智能体能对本地数据进行一系列操作,包括:
读取、清洗数据;分析数据;可视化展示;保存结果等。
⚠️ 这相当于给大语言模型装上了"双手",实现了从"说"到"做"的转变。
4. 交互
在执行任务过程中,智能体具备以下交互能力:
遇到权限等问题时,主动反馈给人类
明确需要人类执行的下一步操作
完成任务后提供改进建议或替代方案
二、大模型智能体 vs 传统规则智能体
灵活性:大模型智能体由于每一个词是基于概率推测出来的,所以能够根据不同的情况做出灵活调整;传统规则AI依赖预设的规则,灵活性较差。
可解释性:传统规则AI的逻辑透明,可以清楚地理解决策过程;而大模型智能体往往是黑箱模型,决策过程不易解释。
开发成本:传统AI系统需要手动编写大量规则,开发成本较高;而大模型智能体基于预训练模型直接开发或微调,成本较低。
前面提到的感知和交互也是大模型智能体和传统规则智能体的一个区别,传统规则智能体只能被动接收数据,然后根据已经构建好的模型对数据进行分析,而大模型智能体可以根据任务目标自动获取数据;另外,传统规则智能体的碰到问题可能会直接报错或者完成任务是就报告完成,而大模型智能体则会尝试各种方案,遇到它解决不了的问题时,会反馈解决这个问题的方案,完成任务后可能会给一些别的建议作为参考。
三、实践:构建你的第一个智能体
以 GLM4.7 为例,展示如何基于大模型构建智能体。
1. 安装 SDK
2.使用python通过api调用大模型:
我也忘了最开始是怎么安装的(我的SDK安装到了D盘的python3.13.5,但vscode打开默认是C盘的3.14.2这个版本,所以安装SDK后进行调用时,出现了报错,只需要修改一下调用的python的位置就行),如果本地环境只有一个python,应该是不会出现我这个问题的。
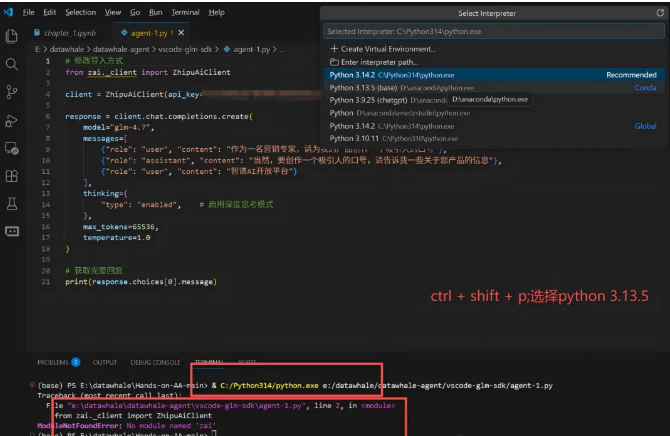
换一个python,就可以成功运行了
为了更方便地与智能体交互,我们需要进行封装(封装完直接在终端运行这个py脚本就可以获得回答了,但是问题需要提前在脚本中编辑好):
from zai._client import ZhipuAiClient # 这里的zai._client是一个内部模块,用于与ZhipuAI API通信,也就是刚才下载的SDK中的_client.py文件class GLMAgent: # 定义一个GLM智能体类,用于与ZhipuAI API通信def __init__(self, api_key, model="glm-4.7",system_prompt="你是一个很聪明的智能体。你会用中文回答用户提出的任何问题。"): # 初始化方法,设置API密钥、模型名称和系统提示词,提示词用于设置智能体的行为和回复风格self.api_key = '***'self.client = ZhipuAiClient(api_key=self.api_key)self.model = modelself.system_prompt = system_promptdef ask(self, question, stream=False): # 定义提问接口,用于与智能体交互,每次只需要输入问题,即可获得智能体的回答response = self.client.chat.completions.create( # 这里的代码用于调用ZhipuAI API的chat.completions.create方法,用于与智能体交互model=self.model, # 该参数指定使用的模型名称,这里是glm-4.7messages=[ # 该参数指定对话内容,是一个列表,每个元素是一个字典,包含角色和内容{"role": "system", "content": self.system_prompt}, # 该参数指定系统提示词,用于设置智能体的行为和回复风格{"role": "user", "content": question}, # 该参数指定用户问题,用于与智能体交互],stream=False # 非流式,一次返回完整回答;与流式回答不同,非流式回答一次返回所有内容,而流式回答是分块返回,每次返回一部分内容)return response.choices[0].message.content # 返回智能体回答内容def update_system_prompt(self, system_prompt): # 更新系统提示词接口,用于在运行时更新智能体的行为和回复风格self.system_prompt = system_promptagent = GLMAgent(api_key='***') # 这里的GLMAgent就是刚才定义的类,可以理解成一种指令,用于创建一个智能体实例,api_key是该命令的参数,用于指定ZhipuAI API的密钥# agent.update_system_prompt("你是一个生物信息学的教授,你会用你的专业知识回答生物信息学的问题") # 更新系统提示词answer1 = agent.ask("请解释详细一下RNA在疾病发生与治疗方面的作用") # 每次将问题作为参数传入ask方法,即可获得智能体的回答print(answer1) # 打印回答
其实,这段代码跟上段代码的功能是一样的,也是只能进行一轮对话,但这段代码相对更容易理解。
四、当前智能体面临的挑战
幻觉问题:作为一个科研工作者,通过大模型给撰写论文,并要求它给附上参考文献,它往往给的参考文献都是看起来很“真实”,但在知网或者其他文献数据库中查无此文,也就是说它在跟你一本正经的胡说八道,这就是“幻觉”。
安全风险:智能体执行错误,除数据泄漏、资金盗用等数字领域的安全外,还将导致物理设备误操作、设备损坏甚至人身安全事故等真实世界损害。
长程依赖问题:AI智能体在长时间运行任务时的记忆断裂与进度丢失难题。我的理解的话,跟智能体的“记忆”有点像,就是因为在人与大模型的多次交互中,为了能够持续的对任务进行分解和优化,人机之间会有多轮对话,而每次大模型的回答都需要将前面所有的对话内容作为新的输入进行分析,所以token的消耗就会呈现指数级的增长,而每次对话的长度是有限的,比如200万token,当本次对话的token达到200万以上,此时大模型的回答可能就会出现明显的“降智”。
复杂任务推理和规划:简单来说,智能体在面对用户的提问时,将任务进行专业的分解,分工和执行的能力,这决定了智能体能否更高效的完成用户的提问(可以大大降低token的消耗,通过将复杂任务进行拆分,可以将子任务合理的分配给更专业的agent,多个agents协同工作,可以更快完成复杂任务)。

本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。