



如何训练 LLM?从数据标注到循环训练,完整流程解析
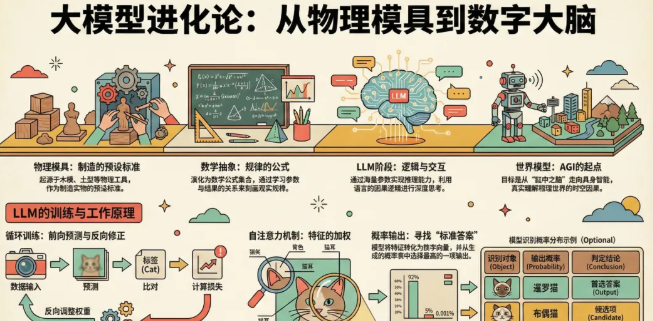
01 |"模型"的演进:物理到数学,赛博飞升还看世界模型
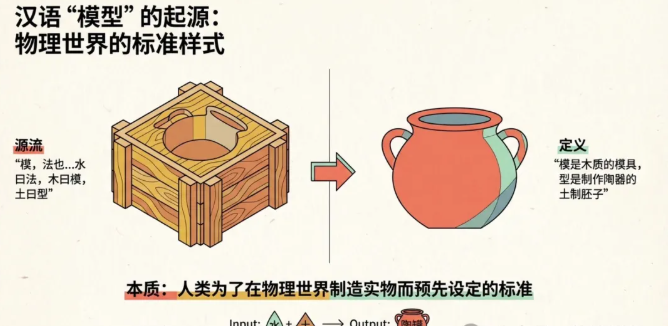
1)汉语“模型”来自物理世界。模,法也。——《说文》。按,水曰法,木曰模,土曰型,金曰镕,竹曰笵。在汉语的起源里,模是木质的模具,型是用来做陶器的土制胚子,是人类为了在物理世界制造实物而预先制造出来的标准样式。
模型:土制胚,中空且膨大,底部平竖放不倾倒
输入:水+土,输出:存水的陶罐
2)模型从物理实物拓展到数学和机器学习领域,演化为“一种现实世界规律的数学抽象集合”,可以认为本质是一套公式组,刻画出了“条件a和参数b,与结果c之间的规律(公式)”,或者是数学概率。在这个阶段有了模型训练的概念,比如电脑通过学习成千上万套房子价格与条件参数之间的关系,逐步刻画出越来越准确的公式关系和概率。
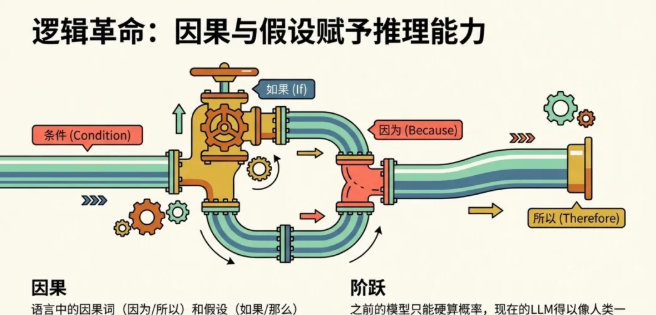
3)进化到大语言模型(LLM)的全新阶段,除了越来越准确的概率,模型具备了推理的能力。“大”模型指模型学习的数据源规模和参数数量变得超大,知识的广度以及掌握的规律范围变得前所未有的大;“语言”的加持,产生了【交互革命】,模型能够以文字输入,以语言输出,极大降低技术门槛【逻辑革命】语言的因果词(因为/所以)和假设(如果/那么)给了模型“逻辑”推理的能力,之前的模型只能硬算概率,现在的LLM得以像人类一样一步步推理和思考【知识架构】语言是三维世界给模型做输入的二向箔!模型通过学习无数篇关于“火焰”的文章,建立一套“火、热、发光、危险”的关联语义空间,虽然模型没见过火,但它似乎知道了火是什么。
4)LLM语言模型和世界模型,尽管LLM的参数和性能越来越强,但他距离AGI还有很远的距离,就像上一段的例子,模型对火再了解,能够写诗写歌帮你炒股,它通过文字学到了因果的逻辑,但缺乏物理的直觉。它知道杯子掉地会碎,但它不知道碎片飞溅的物理轨迹,因为它没有在三维空间中‘生活’过,它仍然是“缸中之脑”,什么时候模型能通过具身感知物理世界,也许才是赛博飞升的起点。
02 |LLM(Large-Language-Model)-如何训练一个模型?
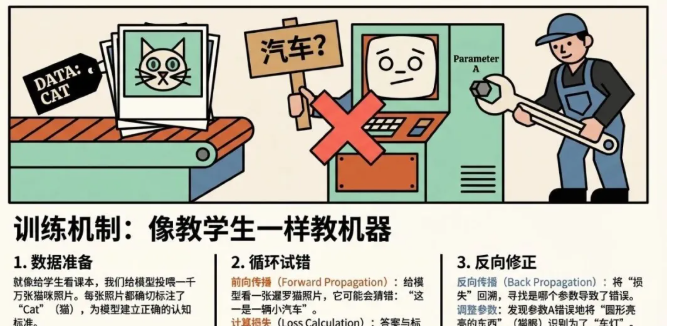
LLM的本质是“给定上下文,通过学习规律,使得AI能够精准猜出下一个词”,以训练一个“猫咪识别模型”为例(尽管这里更像是一个机器视觉的示例,通过一张猫咪照片,精准识别出猫咪的种类),大概分为几个环节
1)数据准备和标注(labeling)-给模型看一千万张猫咪的照片,并在猫咪位置上标注“cat”,为了让模型产生正确的猫的认知
2)执行循环训练 - 不停调整参数以使模型最终猜对的可能性(概率)尽如人意
- Forward Propagation 前向传播,给模型看一张暹罗猫猫的照片,让模型猜结果 - 这张照片是一辆小汽车
- 计算损失,将返回的结果与标注的正确答案做对比,计算损失(loss),损失越大代表结果错的越离谱。同时这里的loss是scaling law中追求的,随模型数据和参数增长,loss的下降是可预期的
- Backward Propagation 反向传播,将损失回溯到各个参数的贡献权重,确认参数需要被更新的程度(参数A-圆形亮亮的对应汽车灯)
3)重复这个过程,直到模型成熟可用
03 |LLM的工作原理,理解问题-思考过程-输出结果
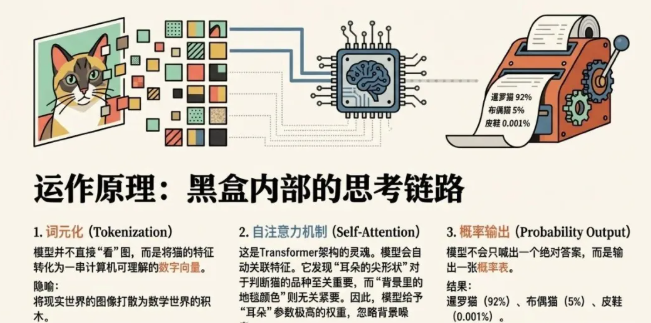
大语言模型(LLM)是基于 Transformer 架构且参数量巨大的 AI 系统,其原理是通过自注意力机制在海量文本数据中学习统计规律,从而实现对下一个词(Token)出现的概率预测
1)词元化(Tokenization):模型将猫的特征转化为一串数字向量。
2)自注意力机制(Self-Attention):transformer架构的核心,模型会自动关联特征,比如发现“耳朵形状”对判断品种比“背景里的地毯颜色”重要得多,因此对“耳朵形状”的参数加权
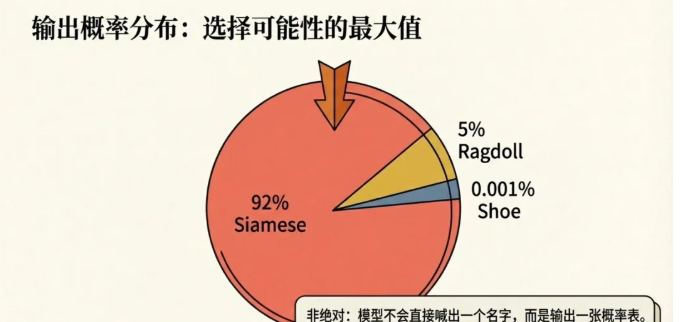
3)输出概率分布:模型最后不会直接喊出一个名字,而是输出一张概率表:暹罗猫 (92%)、布偶猫 (5%)、皮鞋 (0.001%)。它通常选择概率最高的那个作为“标准答案”输出。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。