



小米 MiMo 大模型怎么样?小米 MiMo 大模型好用吗?

两天前,小米正式发布并开源了自己的小米具身基座模型 MiMo-Embodied。我看到的信息是小米自动驾驶 VLA 模型负责人陈龙发的,随后雷军也对微博进行了转载。陈龙对该模型最重要的三个评价是:
- 在自动驾驶和机器人的 29 个基准测试中达到 SOTA;
- 通用视觉语言能力得以保留;
- 成功验证了“统一具身智能大脑”的可行性。
我稍微解释一下,所谓的测试中达到 SOTA,全称是State Of The Art,也就是当前最高水平。当然,这是一个相对概念,因为不同的模型参数量不同,直接对比不合理。就好比拳击运动,需要分公斤级分开较量。所谓 SOTA,就是做到了当前公斤级最强。
后面两个点字面上也比较容易理解,就是说该模型不仅是个多模态大语言知识模型,同样也是一个可以在机器人领域和自动驾驶领域表现优秀的大模型。简单来说就是实现了通识知识、机器人领域、自动驾驶领域方面的融会贯通。
好的,接下来我开始正式评价,这个模型到底处于什么水平,否则大家无法理解。
一如既往的本人风格,我们评价一个事物之前,应该先把评价的逻辑和思考呈现出来,这样所有人首先可以评价你的“评价逻辑”,这是非常重要的。
因为太多的看似理中客的文章,实际上是把你拉进另一套偏颇逻辑。只有在评价“评价逻辑”的合理性后,才能很好的对结果负责。下面我开始陈述:
大模型这个东西,大家或多或少都有概念了。简单一想也很容易清楚,一个大模型知道的越多越正确,那它肯定就最厉害。就好比学生面对考试,拿最高分的学生当然是学习最好的,这毋庸置疑。所以第一个逻辑就很清楚了,看考试分数。
大模型的玩家们也是同样的思考,共同去考一个非常难的试卷,看谁分数高,就能很清楚谁的能力最强。不过这里有一个小小的问题,学生的考卷非常多,大模型也是。比如上学时大家肯定经常会做成都七中、北京四中的考卷,这就说明不同的试卷会反映不同的能力。
所以第一点,我们需要找到一张最有考核价值的试卷。对于大模型来说,就是找到最有权威和公信力的数据测试集。说白话就是大家都用自己的模型去做这些测试,拿最高分的就最厉害。
当然了,如果一个模型宣称自己在几个方面都很厉害,那自然我们要确认这几方面的考卷是否都是最权威的。这是评价的第一个逻辑。
第二点,公开测试集考卷也有一个问题,就是它是公开的。你可以想象如果每个人高考都去考一份固定的公开的考卷,哪怕难度再大,也都能拿高分。要评估这一点就很难了,完全靠大家自觉。除非把所有训练数据、代码全部公开,但并非所有开源都会开这么彻底。
所以行业有一些公司会表现出极高道德自律的行为,比方说会在论文的一个独立章节,讲述自己有没有主动去约束自己的模型提前把考题看一遍,甚至主动剔除可能存在的污染。
这些东西会在章节中用不同程度的说法去申明,效力当然也不一样。就好比会计事务所审计报表给出不同意见一样,无保留意见和保留意见,意义是大不相同的。
所以最牛逼的大模型,就是在最权威的测试集上拿到最高的分数,且表现出最高的道德自律。这是光谱的最右端,也就是最成功最牛逼最毫无争议的 SOTA。有了这个基本概念,我们就能评价小米 MiMo-Embodied 了。
小米对这个模型三方面的能力宣传比较着重,一个是多模态通识能力、一个是具身智能基准测试、一个是自动驾驶基准测试。三种测试,当然需要三种不同的考题。我也不是行业权威,即使我是大家也不一定会信。所以我问了最近最受欢迎最火的 Google 大模型 Gemini 3.5 Pro Thinking。
“如果从大模型能力,具身智能能力和自动驾驶能力三个维度,各挑一个最权威的测试集,是哪三个?”
回答如下:
通用大模型能力 (General Multimodal Capabilities)
文中选用的最权威测试集:
- MMMU (Massive Multi-discipline Multimodal Understanding)
- 理由:这是目前多模态领域公认的“高考”。正如我们刚才分析的,它包含大学水平的图表、科学推理,是衡量模型“智商”和“专家知识”的最高标准。论文选用它,说明敢于直面最难的挑战。
行业公认的最权威测试集:
- MMMU (与文中选择完全一致)
点评:在这个维度上,论文的选择与行业标准完全一致。目前只要是做多模态大模型(GPT-4V, Gemini, Claude),MMMU 都是必测项目。
具身智能能力 (Embodied AI / Robotics)
这里出现了分歧,也是“学院派”和“实战派”的区别所在。
文中选用的最权威测试集:
- SQA3D (Spatial Question Answering in 3D) 或 EgoPlan
- 论文更侧重于“大脑的理解能力”。SQA3D 测试模型能不能理解“在厨房柜子左边的第二个抽屉里”这种空间指令;EgoPlan 测试模型能不能看懂视频并规划下一步做什么。
- 局限:这些更多是离线测试(Open-loop),即“我看图回答对不对”,而不是“我控制机械臂能不能抓起杯子”
行业公认的最权威测试集:
- SimplerEnv / ManiSkill2 (基于模拟器的闭环控制)
- 在具身智能核心圈子(如 CoRL 会议),大家更看重闭环成功率(Success Rate)。比如 SimplerEnv 是目前评估通用机器人策略(Generalist Robot Policy)的最火标准,它要求模型在模拟器里真实地控制机器人去把水龙头关上,或者把积木搭好。
点评:论文在这个维度上有点“避重就轻”。它证明了模型看懂了任务,但没有在最硬核的模拟器里证明它能执行好任务。
自动驾驶能力 (Autonomous Driving)
文中选用的最权威测试集:
- DriveLM (基于 nuScenes 的问答与规划)
- 这是一个新兴的、专门针对“大语言模型做驾驶”的测试集。它不仅看你开得好不好,更看你能不能用语言解释“为什么要减速”。这非常符合 MiMo 作为“大模型”的定位。
行业公认的最权威测试集:
- nuScenes Leaderboard (感知) / CARLA Leaderboard (全栈驾驶)
- nuScenes 是自动驾驶感知的“圣经”,所有车企(特斯拉、蔚来、小鹏)和算法公司都在刷这个榜单的 mAP(精度)。
- CARLA 是全栈驾驶的“斗兽场”,测试模型在复杂交通流中能不能不撞车、不闯红灯地开到终点。
理由:
- nuScenes 是自动驾驶感知的“圣经”,所有车企(特斯拉、蔚来、小鹏)和算法公司都在刷这个榜单的 mAP(精度)。
- CARLA 是全栈驾驶的“斗兽场”,测试模型在复杂交通流中能不能不撞车、不闯红灯地开到终点。
点评:DriveLM 虽然很有前瞻性,但在传统的自动驾驶圈子里,认可度还没有 nuScenes 或 CARLA 那么高。论文证明了模型有很好的“驾驶常识”和“可解释性”,但没法证明它比现在的自动驾驶系统更安全、实际操作能力更强。
结果总结成一张表如下:
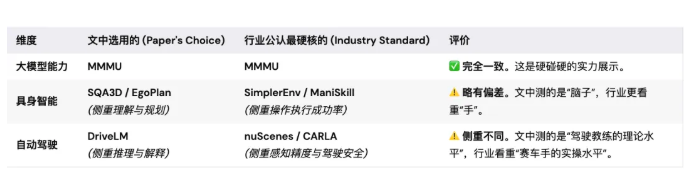
我的点评:
毫无疑问,小米 MiMo-Embodied 在多模态认知能力上,是绝对非常优秀的(同级别较量)。不过小米重点宣传的具身智能和自动驾驶能力层面,选用的测试集更多是考察在相应领域的思考与理解,并不是我们通常意义上理解的机器人综合控制能力与自动驾驶综合控制能力。
这个模型更多的还是在多模态认知层面得分较高,并不能等同于机器人领域很强,也不能等同于自动驾驶很强。甚至我认为和这两个领域真正的关联性比较一般。
剩下的第二个部分,也就是我们前面提到的,关于道德自律的描述。
开源大模型领域的标杆,或者说道德自律要求最高的,我们熟知的模型有三个,Meta 的 Llama 3、阿里的 Qwen 2、以及 DeepSeek V2/V3。这三家都是 Gemini 认为行业道德典范,做了非常详细和用心的去污剔除工作。
小米 MiMo-Embodied在论文中提到的是,使用了“Training Set/Split”。也就是说,小米申明中说的是遵照学术规范和道德使用的训练集。或者换句话说,我理解的意思就是申明:我没有主动作弊。
并没有像最自律的玩家一样,开展详细的去污剔除工作,不过这并没有什么问题。我说这句话时候是中性态度,并没有任何褒义或贬义的意思。
但我们依然需要知道,没有主动作弊和极高的道德自律,依然是有差别的,只是我无法量化其中的差别。
提供一个数据,MMMU 榜单前 20 名主流模型中,80%的模型(如 Llama 3, Qwen2-VL, InternVL)均提供了明确的数据去污声明或 N-gram 过滤流程。小米 MiMo 模型属于少数未明确披露去污细节的模型之一。虽然符合基础学术规范(提及了训练集划分),但在当前严格的大模型评估标准下,缺乏显性的去污证明增加了其测试成绩的不确定性风险。
总结
小米在小参数量大模型领域,取得了非常优秀的成果,多模态通识能力达到行业领先水平。至于在其他领域的表现,我认为无法给出一个明确的评价。这个成绩由于没按照主流做法提供去污申明或剔除检测,含金量或者说诚意一般。
当然,我们无法通过一两个哪怕最权威的测试集去完全定性一个大模型的能力,也有很多同样受认可的测试集,比如马斯克和 Andrej Karpathy 最推崇的Chatbot Arena,后者甚至说“这是目前唯一值得一看的榜单”。有兴趣的话自行了解吧。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。