



一文讲透 Agent 技术:React 模式 + 系统提示词,揭秘 AI 自主执行的底层逻辑

如果把大模型比作一个足智多谋的军师,那它最大的遗憾就是——只能出谋划策,却无法亲自上阵。你让GPT-4o写一个贪吃蛇游戏,它确实能给你完美的代码,但把代码写入文件?抱歉,你得自己动手。想让它基于已有代码改进?不好意思,你必须先把代码复制给它看。
这就是当前大模型的核心局限:无法感知和改变外部环境。它像一个被困在玻璃房里的天才,看得见外面的世界,却触碰不到。
但如果我们给这个天才装上"手脚"和"眼睛"呢?这就是Agent技术要解决的问题。
什么是Agent?一个公式就能说清楚
Agent = 大模型 + 工具集
这个公式简单却深刻。工具就像是大模型的感官和四肢:
- 读写文件的工具,让它能"触摸"代码
- 运行终端命令的工具,让它能"操控"程序
- 网络搜索工具,让它能"探索"信息
有了这些工具,大模型就从"军师"变成了"将军"——不仅能制定策略,还能亲自执行,形成完整的闭环。
典型的Agent应用场景包括:
- 编程Agent(如Cursor):从需求分析到代码实现,全流程自动化
- 研究Agent(如Perplexity):深度搜索、信息整合、报告生成一气呵成
- 办公Agent:自动制作PPT、处理表格、管理文档
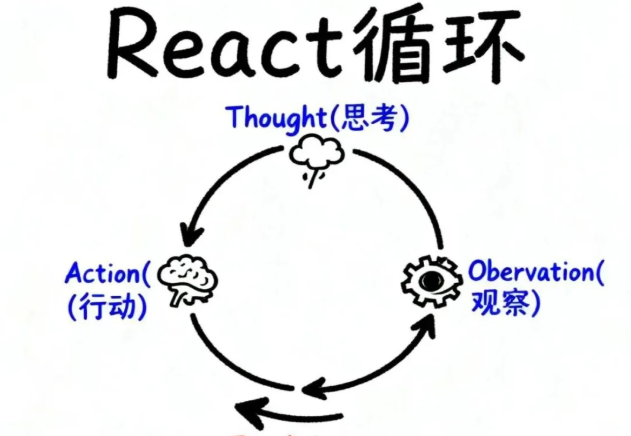
React模式:Agent的"心跳"节奏
Agent如何运作?最经典的答案是React模式(Reasoning and Acting,思考与行动)。这个2022年提出的模式,至今仍是业界主流。
React模式的核心是一个优雅的循环:
思考(Thought)→ 行动(Action)→ 观察(Observation)→ 思考…
让我们用一个真实案例理解这个循环:
任务:写一个贪吃蛇游戏,代码分别放在HTML、CSS、JS三个文件中。
第一轮循环:
- 思考:需要先创建HTML文件作为游戏的基础结构
- 行动:调用write_to_file工具,写入index.html内容
- 观察:工具返回"写入成功"
第二轮循环:
- 思考:HTML已完成,现在需要添加样式
- 行动:调用write_to_file工具,写入style.css内容
- 观察:工具返回"写入成功"
第三轮循环:
- 思考:样式已完成,最后添加游戏逻辑
- 行动:调用write_to_file工具,写入game.js内容
- 观察:工具返回"写入成功"
终止条件:
- 思考:所有必要文件已创建,游戏可以运行
- 最终答案(Final Answer):贪吃蛇游戏已完成,包含HTML、CSS、JS三个文件
这种循环持续进行,直到Agent判断任务完成。每一次观察的结果都会影响下一次思考,形成真正的"智能决策链"。
系统提示词:Agent的"操作手册"
你可能会问:模型怎么知道要按React模式运行?答案藏在系统提示词里。
系统提示词就像给模型编写的"剧本",详细规定了它的角色和行为规则。一个典型的React系统提示词包含五个部分:

1. 职责描述
你需要解决一个任务。为此,你需要将任务分解为多个步骤。 对于每个步骤: - 首先使用<thought>标签思考要做什么 - 然后使用<action>标签调用一个工具 - 工具的执行结果会通过<observation>标签返回给你 持续这个过程,直到你有足够信息提供<final_answer></final_answer></observation></action></thought> 2. 示例演示
通过具体案例展示expected输出格式,让模型理解React循环的节奏。
3. 可用工具清单
列举所有可调用的工具及其参数说明,比如:
- read_file(path) - 读取文件内容
- write_to_file(path, content) - 写入文件
- run_terminal_command(command) - 执行终端命令
4. 注意事项
强调安全规则,例如:运行终端命令前必须获得用户确认。
5. 环境信息
提供操作系统、当前目录、文件列表等上下文信息。
这个"剧本"的精妙之处在于:模型本身并未专门为Agent训练,但通过精心设计的提示词,它就能表现出Agent的行为模式。这就像给演员一个好剧本,即使没有排练,也能演出精彩的戏。
Agent的"大脑"构成:四个关键角色
一个完整的Agent系统由四个角色协同工作:
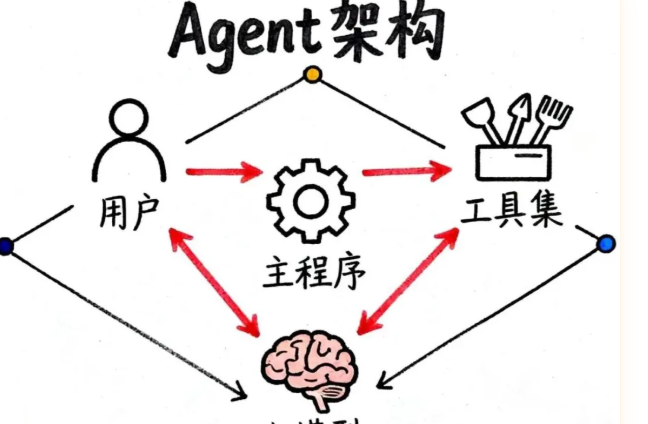
- 用户:提出任务需求
- Agent主程序:核心调度器,负责:
- 大模型:决策中枢,负责思考和规划
- 工具集:执行器,完成具体操作
整个流程可以这样理解:用户是"客户",Agent主程序是"项目经理",大模型是"技术总监",工具集是"执行团队"。项目经理接到客户需求后,向技术总监汇报;技术总监制定方案,由项目经理分配给执行团队;执行结果再反馈给技术总监,直到项目完成。
Plan-Execute模式:先谋而后动
React模式是"边想边做",而Plan-Execute模式则是"先谋后动"——先制定完整计划,再逐步执行。
这种模式在复杂任务中更有优势。想象你要调研几款手机的性能对比:
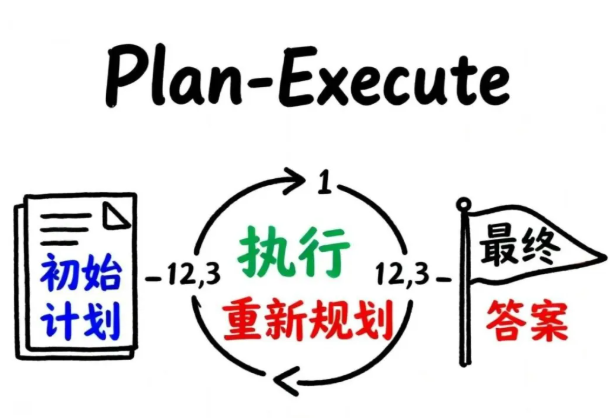
初始计划阶段:
- Plan模型接到任务:“比较今年澳网男子冠军的家乡在哪里”
- 生成执行计划:
执行与重新规划循环:
- 第一轮:执行Agent查询日期→返回"2025年"
- RePlan:更新计划为"查询2025年澳网冠军"(计划变得更具体)
- 第二轮:执行Agent查询冠军→返回"Jannik Sinner"
- Replan:更新计划为"查询Sinner的家乡"
- 第三轮:执行Agent查询家乡→返回"意大利圣坎迪多"
- 终止:RePlay模型判断任务完成,返回最终答案
Plan-Execute模式的核心优势是动态调整能力。初始计划可能不够精确,但随着每一步的执行结果,RePlay模型会不断优化计划,就像GPS导航会根据实时路况调整路线一样。
这种模式特别适合:
- 信息获取有先后依赖的任务
- 需要多步推理的复杂问题
- 对执行效率有较高要求的场景
Agent技术的现实应用
从理论到实践,Agent技术已经在多个领域展现价值:
1. 编程领域
- Cursor:最热门的AI编程助手,集成React模式,能理解项目上下文,自动修改多个文件
- Claude Code:Anthropic推出的编程Agent,支持复杂的代码重构任务
2. 研究与信息获取
- Perplexity Pro:深度搜索Agent,能自动构建研究框架,遍历相关网页,生成结构化报告
- NotebookLM:Google的研究助手,基于上传文档生成播客式总结
3. 办公自动化
- 自动化报表生成
- 智能文档管理
- 会议纪要整理与行动项提取
从"工具人"到"合作者"
Agent技术的本质,是让AI从"被动响应"转向"主动执行"。它不再是你手中的工具,而是你的数字合作者——理解你的意图,主动规划方案,自主完成任务。
当然,Agent技术仍在快速演进中。当前的挑战包括:
- 可靠性:如何确保Agent在长链路任务中不出错?
- 安全性:如何防止Agent执行危险操作?
- 成本控制:多轮调用模型的费用如何优化?
但方向已经明确:未来的AI应用,都将是Agent形态的。从Cursor的成功可以看出,用户真正需要的不是一个"聊天机器人",而是一个能真正帮你完成工作的"数字同事"。
系统提示词就是这个"同事"的工作手册,而React和Plan-Execute则是它的工作方法论。掌握了这些,你就拥有了驾驭AI的真正能力——不是让AI回答问题,而是让AI解决问题。
这才是Agent时代的真正意义所在。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。