



AI大模型的从原理是什么?怎么应用的?

在当今数字化时代,AI 大模型早已不是陌生词汇 —— 从日常聊天的 ChatGPT,到帮我们处理工作的智能助手,它正悄悄改变着我们的生活与工作节奏。但对大多数人来说,AI 大模型就像个 “黑盒子”:知道它好用,却搞不懂它到底是什么。今天,我们就把这个 “黑盒子” 拆开,用大家都能听懂的话,再配上直观的图示,带你全方位搞懂 AI 大模型。
一、先分清:模型与产品不是一回事
聊 AI 大模型时,很多人都会把 “模型” 和 “产品” 弄混。其实这俩的关系特别好理解:就像汽车的 “引擎” 和 “整车”—— 引擎是核心动力,但光有引擎,普通人没法直接用;得配上车身、方向盘、操作系统,变成一辆完整的汽车,才能开上路。
拿大家最熟悉的 GPT 和 ChatGPT 举例:
•GPT 的全称是 Generative Pre-trained Transformer(生成式预训练变换器),它是 Google 2017 年提出 Transformer 架构后,OpenAI 在 2018 年首次做出的 “语言大脑”—— 能读懂文字,也能生成文字,这就是模型,相当于“引擎”。
•而 ChatGPT 是在 GPT 这个 “引擎” 基础上,打造出的一款能直接用的应用产品。它比单纯的模型多了三个关键能力:
a.听得懂指令:不管你是随口问“今天吃啥”,还是认真提 “写个工作计划”,它都能 get 到你的真实需求;
b.输出更安全:会过滤不当内容,避免说敏感话题,不用担心它“乱说话”;
c.用着更方便:支持多轮聊天(比如你接着上句话追问)、看聊天记录,还能装插件(比如让它帮你查天气、算数据)。
这种“模型 + 产品” 的搭配,在国内外科技公司里很常见,结合核心关系与对应实例的图示如下:

图示1:AI模型与产品的“引擎-整车”关系图
| 科技公司 | 模型 | 产品 |
| OpenAI | GPT 系列 | ChatGPT |
| 阿里巴巴 | 通义千问(Qwen 模型) | 通义 APP |
| 百度 | 文心大模型(ERNIE) | 文心一言 |
| 腾讯 | 混元大模型(Hunyuan 模型) | 腾讯混元助手 |
| 字节跳动 | 火山引擎大模型 | 豆包 |
二、大模型本质:超级厉害的“填空高手”
如果用一个比喻形容大模型,那它就是个“填空大神”—— 比我们小时候做语文填空厉害多了。
比如给一句话:“小明今天很\\_。” 我们可能只会填 “开心”“难过” 这些常见词,但大模型会根据上下文(比如前面提到 “小明考试考了 100 分”),精准 “猜” 出最贴合的词,比如 “开心”。
它为啥能做到?其实可以用初中数学的函数公式理解:y = Ax + b。
•这里的 x 是 “输入”:可以是一段文字(比如 “小明今天很”)、一张图片(比如一张猫的照片),甚至一段声音(比如你说的一句话);
•y 是 “输出”:比如帮你填出 “开心”、判断图片里是 “猫”、把你说的话转成文字;
•A 和 b 是 “模型参数”:相当于大模型的 “记忆”,它就是靠调整这两个值,算出最合理的输出。
大模型的“学习过程” 也很简单:
1.我们给它喂大量数据(比如海量文章)当样本 x;
2.它根据当前的 A 和 b,算出一个预测结果 y_pred(比如填 “难过”);
3.拿这个结果和“真实答案” y_true(比如原文里其实是 “开心”)比,看差多少 —— 这个差距靠 “损失函数”(相当于 “评分标准”)来衡量;
4.差距大了,就调整 A 和 b,再算一次;直到差距小到几乎不变,就说明模型 “学会了”,这在专业上叫 “收敛”。
这里有个关键知识点:别看过程像“有人教它对错”(监督学习),其实大模型用的是 “自监督学习”—— 不用人标注答案,数据自己就能当 “老师”。
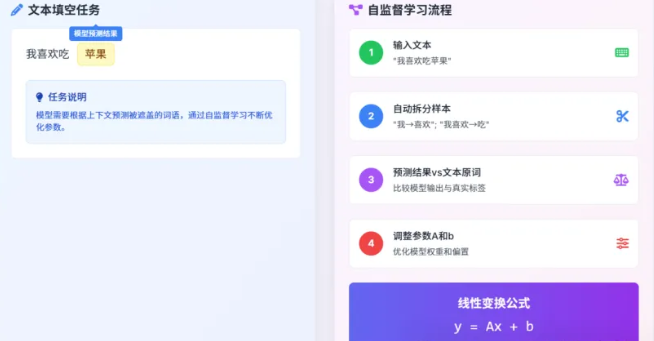
比如输入“我喜欢吃苹果”:
•给模型看“我”,让它猜下一个词,真实答案就是原文里的 “喜欢”;
•给模型看“我喜欢”,让它猜下一个词,真实答案就是原文里的 “吃”;
•给模型看“我喜欢吃”,让它猜下一个词,真实答案就是原文里的 “苹果”。
所以大模型的学习逻辑是:从海量文本里自己找“练习题”,每道题的 “正确答案” 就是文本里的下一个词,不用人动手标;它靠猜下一个词,慢慢摸清语言规律 —— 这就是 “自监督学习” 的意思,对应的学习流程图示如下:
说到底,AI 模型就是一个 “高级函数”:接收输入,算一算,输出结果。但它和初中函数的区别在于:初中函数只有 A、b 两个参数,而现代大模型的参数有百亿、甚至千亿个 —— 这些参数就是它学来的 “知识”,像大脑里的神经元一样,存着它对语言、世界、逻辑的理解,能快速算出 “哪个答案最对”。
三、大模型底层原理:“超级公式机” 的奥秘
看到这,你可能会问:要是一句话有十几个词,甚至一篇文章有上千个词,就靠 y=Ax+b 这一个公式,能处理得过来吗?
答案是“不够用”。所以现在主流的做法是:把 y=Ax+b “叠起来用”—— 不是只用一层,而是堆很多层,每一层都做类似 y=Ax+b 的计算,再把结果传给下一层,而且每一层的 A 都不一样。就像加工食材:先切、再腌、再炒、最后调味,越加工越精细,最后能做出复杂的 “大餐”—— 这就相当于把无数个 y=Ax+b 拼起来,变成了 “超级大公式”。
现在大部分大模型,都基于“Transformer 架构”,如下图所示。别看名字复杂,其实就是一连串 y=Ax+b 在 “干活”,再加上一个 “关键技能”。
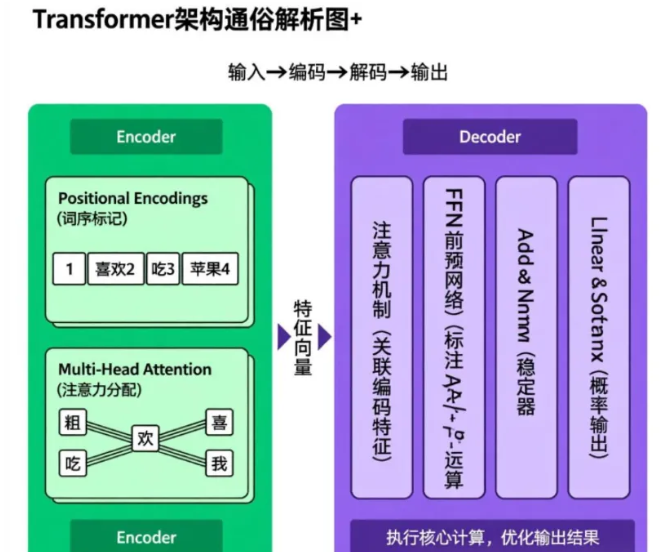
Transformer 架构的 “绝招”,是除了每层都算 y=Ax+b,还加了 “注意力机制”(Attention)。简单说就是:Transformer = 一堆 y=Ax+b + 会动的 A(注意力)。
普通的 y=Ax+b 里,每个输入都被 “一视同仁”—— 比如看 “我喜欢吃苹果”,会把 “我”“喜欢”“吃”“苹果” 看得一样重要。但实际语言里,词的重要性不一样:比如要猜 “吃” 后面是什么词,更该关注 “喜欢”(喜欢吃什么),而不是 “我”(谁喜欢不重要)。
注意力机制就像“会动的 A”:它能根据输入的内容,自动判断 “该重点看哪个词”。比如猜 “吃” 的下一个词时,会给 “喜欢” 更高的 “注意力权重”,给 “我” 更低的权重。
所以在 Transformer 里,公式变成了y ≈ A(x)·x + b—— 这里的 A (x) 不是固定的数,而是根据输入 x 算出来的 “注意力权重”。换句话说,Transformer 把原来 “死板的 A”,变成了 “会思考的 A”:能根据上下文调整关注重点,这就是大模型能读懂长文章、写出通顺回答的核心秘密。
另外,输入文字时,大模型还要做两步准备:
1.用“tokenizer” 把文字拆成 “小片段”(比如把 “我喜欢吃苹果” 拆成 “我”“喜欢”“吃”“苹果”),这些小片段叫 “token”;
2.给每个 token 做 “embedding”(嵌入)—— 简单说就是把文字变成电脑能算的数字,再传给后面的网络。
至于 Transformer 的 “用法”,不同模型也不一样:
•只用车头(Encoder):比如 BERT、RoBERTa,擅长 “读文字”—— 做分类(比如判断文章是正面还是负面)、问答(比如从文章里找答案)、识别名字(比如从句子里挑出 “小明” 这个人名);
•只用车尾(Decoder):比如 GPT 系列、LLaMA,擅长 “写文字”—— 聊天、写文章、写代码;
•车头车尾都用(Encoder+Decoder):比如 T5、BART,擅长 “先读再写”—— 翻译(先读懂中文,再写成英文)、写摘要(先读懂长文,再写成短文)。
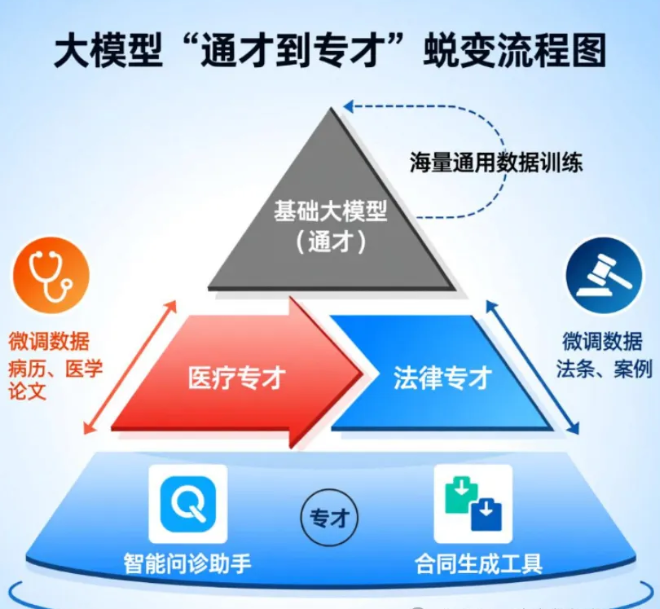
四、实际应用:从“通才” 到 “专才” 的蜕变
用互联网海量数据训练出来的大模型,其实只是个“基础款”—— 相当于有了一个 “会说话、会写字的底层大脑”,是个 “通才”:知道的多,但在具体领域可能 “不精通”。比如一个基础大模型,可能懂点医学知识,但没法像医生一样精准看病;懂点法律知识,但没法像律师一样写合同。
想让它在某个领域“好用”,就得做 “微调”—— 用这个领域的精准数据,再训练一次。这一从“通才”到“专才”的蜕变过程,可通过以下图示清晰呈现:
还是拿 GPT 和 ChatGPT 举例:
•GPT 是 “基础大模型”:懂天文地理,但你让它 “帮我写个职场周报”,它可能写得不够贴合需求;
•ChatGPT 是在 GPT 基础上 “微调” 过的:专门训练了 “理解人类指令” 的能力 —— 你说 “写周报”,它会问你 “这周做了哪些工作”“有没有重点项目”,最后写出符合职场需求的内容,变成大家能直接用的产品。
再举个聊天的实际例子:你说“我今天很……”,大模型会立刻在 “大脑” 里翻找海量数据,算出每个可能词的概率:“开心” 80%、“忙” 10%、“生气” 5%…… 最后挑概率最高、最贴合你上下文的词回复你。接着你说 “因为考试考了 100 分”,它又会根据这句话,调整概率,接着猜下一个词,慢慢聊出完整的对话。
所以总结下来,大模型就是这么个东西:
•靠“记忆力”:读过海量文本,存了很多知识;
•靠“计算力”:百亿级参数飞快运算,算得又快又准;
•靠“猜词游戏”:一步步预测下一个词,实现聊天、写文、解题。
相信看到这,你对 AI 大模型已经有了清晰的认识。后面我们还会专门拆解文中提到的 “tokenizer”“embedding” 这些专业词,用更简单的方式讲明白,带你进一步走进 AI 大模型的世界。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。