



什么是多模态大模型?多模态大模型在各行业的应用场景与价值

多模态大模型(Multimodal Large Language Models,MLLMs)是人工智能领域的前沿技术,能够同时处理和理解文本、图像、音频、视频等多种数据形式,实现跨模态信息的融合与交互。这种能力使得AI系统能够更全面地理解世界,处理复杂的现实问题,为各行业的数字化转型提供了强大动力。本文将从多模态大模型的定义、技术架构、代表模型、应用场景以及发展趋势等方面进行深入解析。
一、多模态大模型的定义与核心特点
多模态大模型是指通过整合文本、图像、视频、音频等多类型数据进行联合训练的深度学习模型。与传统单模态模型不同,多模态大模型采用跨模态编码器训练、语义对齐与特征融合等核心技术,能够实现对不同类型数据的统一表征和相互生成。
多模态大模型的核心特点包括:
1.跨模态理解能力:能够同时理解文本、图像、音频等多种信息,例如分析一张图片并回答相关问题,或理解一段视频中的动作和对话内容。
2.上下文感知增强:在多模态环境中,模型能保持更好的上下文理解能力,例如在医疗诊断中结合患者病历和医学影像进行综合判断。
3.应用领域广泛:适用于图像描述生成、视频内容分析、多媒体问答、文档理解等多种场景。
4.人机交互自然化:提供更加自然和直观的人机交互体验,如结合语音、图像和文本的智能客服系统。
二、多模态大模型的技术架构与实现方法
1. 技术架构
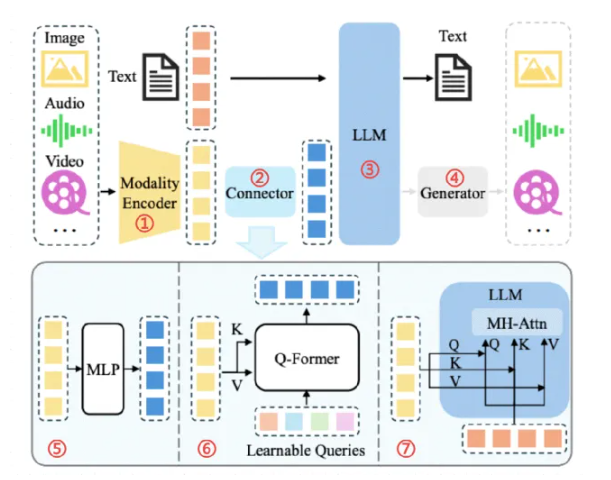
多模态大模型通常基于大型语言模型(LLM)作为核心,通过添加多模态编码器和模态接口来实现对不同类型数据的处理能力。其典型架构包括:
l 模态编码器(Modality Encoder):负责处理视觉、语音等非文本信号,将不同模态的数据转换为模型可理解的向量表示。
l 输入投影器(Input Projector):将不同模态的输入数据映射到共享的语义空间,实现跨模态对齐。
l 大型语言模型(LLM):作为核心认知引擎,处理文本数据并进行推理。
l 输出投影器(Output Projector):将模型生成的输出映射回原始模态的空间。
l 模态生成器(Modality Generator):根据输入数据生成对应的输出数据,如图像或视频。
2. 主要技术路径
多模态大模型主要采用三种技术路径:
1)LLM协同架构:通过ChatGPT等语言模型进行任务调度,调用HuggingFace平台的多模态组件(如图像识别、语音处理模型)完成跨模态任务。微软亚洲研究院2023年5月发布的HuggingGPT框架即采用此方案。
2)联合训练方法:基于单模态编码器和Transformer架构实现特征交互,依赖大规模对齐语料库构建跨模态映射。典型模型包括CLIP(图像-文本对比学习)、VideoBERT(视频-文本对齐)等。
3)跨模态编码训练:以LLaVA模型为代表,通过冻结LLM参数并训练轻量级编码器,实现多模态数据与语言模型的融合。
3. 核心技术
多模态大模型的核心技术包括:
l 混合专家(MoE)架构:通过"分治"原则,将输入路由到不同专家模型(如视觉、文本专家),提升多模态任务的效率和扩展性。例如Switch Transformers和VisionMoE等模型。
l 多头隐变量注意力机制:允许模型在不同模态间进行复杂的注意力交互,提升跨模态信息融合能力。
l 跨模态语义对齐:通过对比学习等方法,将不同模态的数据映射到共享的语义空间。CLIP和ALIGN等模型通过图文配对数据,最小化正样本对的嵌入距离,最大化负样本对距离实现这一目标。
l 轻量化技术:包括蒸馏、量化、剪枝等方法,通过逆向KL散度策略提升蒸馏质量,GPTQ通过最小化权重距离优化部署效率,以及针对模型依赖结构进行的剪枝技术。
三、多模态大模型的代表模型与性能表现
2024-2025年是多模态大模型的爆发年,众多厂商发布了具有代表性的多模态模型:
1.OpenAI系列:GPT-4V(Vision)在GPT-4基础上增加了视觉理解能力,能够处理图像和文本的复合输入。GPT-4o模型进一步支持音频输入,实现真正的多模态交互。在各类评测中,GPT-4o在纯文本和多模态任务中均展现了优异的性能。
2.Anthropic Claude3.5Sonnet:在编程、数学推理和视觉理解方面表现突出,特别是在代码生成和调试任务上超越了许多竞争对手。该模型支持图像分析、文档理解等功能,在多模态benchmark测试中取得了优异成绩。
3.Google Gemini系列:Gemini1.5Pro支持图像、音频和视频输入,能够处理长达数小时的视频内容。Gemini2.0Flash则是一个All-in-one自带Agent架构的多模态模型,可以实时接收文字、语音、图像、视频等多模态输入。
4.国产模型:如"紫东太初"大模型2.0版实现文本、图片、语音、视频等模态的统一表征和学习;自然资源部发布的深海生境多模态大模型DePTH-GPT,可协同处理视频、地形、水动力等多源数据,完成深海生境智能感知与决策支持;Unity中国宣布其"团结引擎"与多模态大模型形成技术互补关系,相关模型部分训练数据来自游戏引擎生成内容,并侧重视觉生成领域应用。
四、多模态大模型在各行业的应用场景与价值
1. 医疗健康领域
多模态大模型在医疗健康领域展现出巨大价值:
l 数字中医:北京智谱华章科技有限公司与中国北京中医药大学东方医院合作,基于GLM-130B大模型构建数字中医服务平台,"复刻"名老中医诊疗经验和学术思想,探索形成与名老中医高度匹配的高危肺结节人工智能临床诊疗解决方案。该模型已开发医疗垂直领域的问答功能,支持对医疗、健康问题进行智能化知识问答,以及根据症状生成中医诊方并提供处方主治症候医学解释等辅助诊疗功能。
l 医学影像分析:Med-MLLM等模型整合医学影像(如X光、CT)与文本报告,支持罕见病诊断,即使在仅有1%标注数据的情况下也能保持81.9%的准确率。PeFoMed通过参数高效微调,处理开放性医学问题(如Med-VQA),减少资源消耗。
2. 城市建设与治理领域
多模态大模型为城市治理带来革命性变化:
l 城市大脑:北京市经开区依托百度智能云泛政多模态大模型构建全流程智能化治理平台,通过精准算法分析,提取四千余种城市治理要素的结构化数据,将视频转化为动态事件流与数据流,实现城市治理问题的智能发现预警、自动立案追踪、案件审核结案等。平台已接入北京市经开区全域视频,实现对百余种城市治理场景的全天候巡检。
l 大型活动保障:在2025年全球首个人形机器人半程马拉松赛事中,多模态大模型通过少量样本图片快速训练出"铁马倒伏"等临时特殊算法,对沿线七百多路摄像头进行灵活配置,有效辅助保障人力的精准调配,确保活动秩序井然。
l 防汛应急响应:面对上千路视频防汛点位,多模态大模型实现分钟级检索,迅速识别并筛选出积水点位,根据积水程度进行分级预警,大幅提升防汛应急响应效率。
3. 建筑与工程领域
多模态大模型赋能建筑行业智能化升级:
l 建筑工程全闭环智能应用系统:中国科学院自动化研究所与中铁建设集团联合研发的系统,整合政府监管、建设、施工、设计、监理、咨询等多源异构工程数据,覆盖建筑行业规范标准、法律文件、技术方案等电子文件超3万本,形成项目地图索引、实时视频通话、风险快速传达、问题整改、自动回复等功能,赋能工程方案设计、技术文件审核等多个阶段全闭环场景,大大提升建筑行业智能化水平。
4. 游戏与文创领域
多模态大模型为游戏与文创产业注入新活力:
l 视觉生成应用:Unity中国利用游戏引擎生成内容训练多模态模型,侧重视觉生成领域应用,为游戏开发提供创意支持。例如,通过指令"生成科幻风格场景",模型可以快速生成符合要求的3D场景设计。
l 文博智推官:百度文心大模型与中国文物交流中心合作,发布首个文博智能体——"文夭夭"文博智推官,为公众提供国内外博物馆文物、展览、数字化应用等文博专业知识的科普讲解、传播推广,实现文物展示水平的提升和文化内涵的重塑。
5. 教育领域
多模态大模型正在重塑教育模式:
l 虚拟教师与智能辅导:GPT-4V用于科学绘图评分(准确率51%)、教材插图分析、语言学习支持(如英语、数学),实现个性化教学。
l 精准教学支持体系:基于多模态大模型的精准教学支持系统框架和面向个性化教育的云边协同基础设施架构,能够实现规模化教育与个性化培养的有机结合,彻底转变精准教学和个性化学习的方式。
6. 金融领域
多模态大模型为金融业带来效率与价值提升:
l 信贷分析:蚂蚁集团"蚂小财"模型覆盖6大类66小类场景,反洗钱误报率低至0.3%;多家证券机构通过私有化部署和垂直场景定制,实现业务效能的指数级提升,如广发证券的"广发智汇"平台缩短投资决策链条。
l 智能客服:邮储银行使用文心金融版,人力成本直接省了45%;某头部银行集成DeepSeek-R1构建智能编程协作平台,解决需求理解偏差问题,代码重复率下降35%。
l 投研分析:通过语音转文字和多模态音频理解,将路演视频内容结构化,提取关键信息,节省看视频时间,提升信息提取效率。
7. 零售与电商领域
多模态大模型重塑零售业态:
l AI数智门店:行行通集团发布的全球首个AI数智门店多模态大模型,能够实时监控视频分析客流、语音情感计算优化服务,运营效率提升30%,GMV增长45%。该模型整合视觉识别、数据中台和智能决策系统,实现门店智能化运营。
l 商品管理:阿里巴巴部署的KG-enhanced多模态大模型,在商品对齐场景中使GMV提升45%,在购物指南场景中使CPM提升28.1%,在QA推荐场景中使点击率提升11%,在新品发布场景中使效率提升30%。
8. 自动驾驶领域
多模态大模型提升自动驾驶感知与决策能力:
l 环境感知:多模态模型整合摄像头捕捉的图像、雷达和激光雷达(LiDAR)收集的数据以及车辆传感器提供的信息,实现更准确的环境感知和决策。在恶劣天气条件下,即使视觉信息受限,也能根据其他模态的数据做出准确判断,提高安全性。
l 决策支持:通过处理多源数据,模型能够预测潜在危险,优化驾驶路径,提高自动驾驶系统的安全性和可靠性。
五、多模态大模型的发展趋势与挑战
1. 发展趋势
l 向轻量化方向演进:多模态大模型正逐步向轻量化方向发展,通过"模型即服务"模式实现三级部署,使更多企业能够负担得起并灵活应用。
l 多模态生成能力增强:从简单的图文描述向视频、3D模型等更复杂的模态生成发展,如文心大模型4.5Turbo实现了文本、图像和视频的混合训练,大幅提升跨模态学习效率和多模态融合效果,使学习效率提高近2倍,多模态理解效果提升超过30%。
l 多模态Agent架构普及:如百度文心大模型与中国文物交流中心合作的文博智能体,以及Google Gemini2.0Flash的Agent架构,使模型能够自主完成多模态任务的规划与执行。
2. 面临的挑战
l 数据对齐与融合:确保不同模态的数据在时间和内容上的一致性,以及如何有效整合多模态数据,以充分利用各模态的信息。
l 跨模态语义对齐:构建统一的表示空间,使不同模态的数据能够互相理解和结合,这是多模态模型的核心技术挑战。
l 幻觉问题:多模态大模型在生成内容时可能出现不准确或虚构的信息,如医疗领域可能出现虚构病灶等问题,需要通过外挂知识库和算法优化提升生成内容的准确性。
l 部署成本高:多模态大模型因庞大的参数量,在资源有限的部署场景下面临挑战,需通过蒸馏、量化、剪枝等方式降低模型参数。
六、多模态大模型与单模态模型的区别
多模态大模型与传统单模态模型在多个方面存在显著差异:
| 对比维度 | 多模态大模型 | 传统单模态模型 |
| 数据处理能力 | 能同时处理文本、图像、音频、视频等多种数据类型 | 仅能处理单一数据类型(如纯文本或纯图像) |
| 任务复杂度 | 支持跨模态任务(如"根据文本生成视频"或"根据音频识别图像场景") | 仅能处理单一模态任务 |
| 应用场景 | 应用场景广泛,如医疗影像分析、智能家居、自动驾驶等 | 应用场景相对单一,如仅限文本处理或仅限图像识别 |
| 参数规模 | 通常具有大规模参数(如34B的Emu3.5模型) | 参数规模相对较小 |
| 训练数据 | 依赖多模态混合数据(如图文混合数据占比70%) | 依赖单一模态数据 |
| 技术挑战 | 需解决数据对齐、语义对齐、特征融合等复杂问题 | 技术挑战相对简单 |
七、多模态大模型的未来展望
多模态大模型代表了AI发展的新方向,通过整合多种数据模态,实现了更接近人类认知的综合智能。未来,多模态大模型将沿着以下方向发展:
1.模态种类持续扩展:从现有的文本、图像、音频、视频向更多模态(如3D点云、传感器数据、触觉信息等)扩展,实现更全面的感知能力。
2.轻量化与高效部署:通过模型压缩、知识蒸馏等技术,降低模型参数量和计算资源需求,使多模态大模型能够在更多终端设备上高效运行。
3.跨模态对齐技术优化:改进对比学习、指令微调等跨模态对齐算法,提高不同模态间的信息融合质量,减少幻觉问题。
4.行业垂直化应用深化:针对不同行业需求,开发更专业的多模态大模型,如医疗、教育、金融等领域的垂直模型,提供更精准的服务。
5.人机交互更加自然:进一步提升多模态大模型的交互能力,使AI系统能够像人类一样,通过多种感官和表达方式与用户进行自然交互。
随着多模态大模型技术的不断成熟,其在各行业的应用将更加广泛和深入,为人类社会带来更智能、更高效的服务体验。
总结
多模态大模型通过整合多种数据模态,实现了对现实世界的全面理解和交互,为AI系统带来更接近人类认知的综合能力。从技术架构到应用场景,多模态大模型正在重塑AI的发展路径和应用边界。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。