



AI视频创作工具的交互模式分类与解析

随着AI技术的快速发展,视频创作工具正在经历一场交互革命。对于个人创作者而言,理解不同工具的交互模式,是选择合适创作工具的关键。本文将系统梳理当前AI视频创作工具的主要交互范式。
一、AI视频创作工具的六种交互模式对比
| 交互模式 | 代表产品 | 核心特征 | 操作方式 | 适用场景 | 主要优势 | 主要局限 | 学习成本 | 制作效率 |
| 工作流式画布 | Tapnow | 节点式可视化编排,每个环节可独立控制 | 拖拽节点+参数配置 | 专业创作、批量生产、商业项目 | 精确控制每个参数 流程可复用分享 | 学习曲线陡峭 操作步骤繁多 | ⭐⭐⭐⭐⭐ | ⭐⭐ |
| 对话式画布 | 即梦(JiMeng) | 自然语言描述,AI理解执行 | 文字对话+多轮迭代 | 创意验证、新手创作、艺术表达 | 零门槛上手 快速捕捉灵感 | 依赖AI理解 精确控制困难 | ⭐ | ⭐⭐⭐⭐ |
| 一键生成智能体 | 纳米AI视频智能体 | 高度封装,端到端自动化 | 一键触发+自动生成 | 自媒体运营、标准化内容、营销场景 | 操作最简单 效率最高 | 个性化受限 难满足特殊需求 | ⭐ | ⭐⭐⭐⭐⭐ |
| 脚本编辑器模式 | Runway、Pika | 生成+调参混合 | 提示词输入→参数面板微调 | 需要一定控制力的快速创作 | 平衡效率与控制 渐进式优化 | 参数理解有门槛 调参耗时 | ⭐⭐⭐ | ⭐⭐⭐ |
| 模板填充式 | 剪映AI模板 | 预设模板+素材替换 | 选模板→填素材→自动成片 | 标准化内容、节日营销、产品展示 | 零基础可用 风格稳定统一 | 创意受模板限制 同质化风险高 | ⭐ | ⭐⭐⭐⭐⭐ |
| 多模态输入混合式 | Sora、可灵 | 文本+图片+视频多种输入 | 多模态组合表达 | 复杂创意、风格迁移、分镜动画 | 表达最自然 输入最灵活 | 对AI能力要求高 结果不确定性大 | ⭐⭐ | ⭐⭐⭐ |
表格说明:
·学习成本:⭐越多代表需要投入的学习时间越长
·制作效率:⭐越多代表从构思到成片的速度越快
·实际产品往往融合多种交互模式,此处分类为主导交互特征
二、交互模式背后的本质权衡
所有交互模式的设计,本质上都在平衡两个核心维度:控制精度与使用门槛
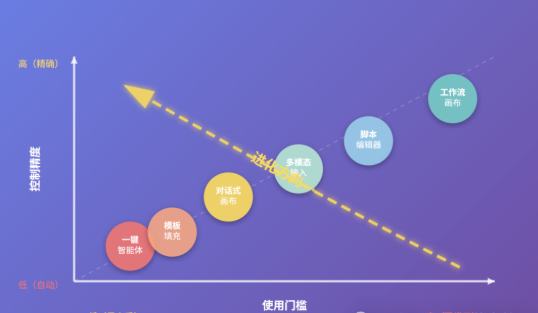
从图中可以看出三个关键规律:
1.对角线分布:所有工具沿着"低门槛低控制 → 高门槛高控制"的对角线分布,这是技术产品设计的必然权衡
2.用户分层:
o新手用户区(左下):一键智能体、模板填充 → 快速上手,标准化输出
o进阶用户区(中部):对话式、多模态 → 平衡创意与效率
o专业用户区(右上):脚本编辑器、工作流画布 → 精确控制,专业产出
3.进化趋势:未来AI工具的发展方向是"打破对角线"——在保持低门槛的同时提供高控制精度,即图中虚线箭头所示的"向左上方突破"
实际选择策略:
·专业创作者:沿对角线右上方选择,牺牲效率换取精确控制
·快速创作者:沿对角线左下方选择,牺牲控制换取效率
·成长型创作者:沿对角线逐步迁移,从模板 → 对话式 → 工作流
三、混合型趋势与未来展望
1. 当前产品的混合交互实践
值得注意的是,实际产品很少采用单一交互模式,而是根据用户需求场景,灵活组合多种交互方式。这种混合交互策略正在成为主流。
典型混合案例分析:
Runway Gen-3:三层交互架构
·入门层:文本提示词(对话式)→ 快速生成初稿
·进阶层:运动笔刷(可视化控制)→ 精确控制镜头运动轨迹
·专业层:参数面板(脚本编辑器)→ 微调光影、速度、风格强度
用户旅程:新手用文本快速出片 → 熟练后用笔刷控制运动 → 专业需求时调参数面板
剪映专业版:场景化交互切换
·快速模式:AI模板库(模板填充式)→ 3分钟完成节日祝福视频
·创作模式:时间轴编辑+特效面板(传统工作流)→ 精细剪辑
·辅助模式:AI对话助手(对话式)→ "帮我去除视频水印" "自动识别并删除停顿"
核心优势:根据任务复杂度自动推荐交互模式,降低认知负担
Midjourney:参数化对话系统
·基础层:自然语言描述(对话式)
·控制层:斜杠命令参数(--ar 16:9 --stylize 750)
·引导层:图片URL引导(多模态输入)
·迭代层:Vary/Zoom/Pan按钮(可视化操作)
设计哲学:用户可以完全用自然语言,也可以逐步深入到参数级控制
2. 混合交互的三大设计模式
模式A:渐进式揭示(Progressive Disclosure)
设计原则:默认简单界面,随用户熟练度逐步暴露高级功能
实现方式:
·新用户看到:一个输入框 + "生成"按钮
·点击"高级选项":展开参数面板
·开启"专业模式":显示工作流画布
案例:Canva的"设计"→"自定义尺寸"→"品牌套件"→"API接入" 层层递进
模式B:任务路由(Task-based Routing)
设计原则:根据用户意图自动推荐最合适的交互模式
实现方式:
用户输入:"制作一个生日祝福视频"
↓ AI分析
- 关键词:生日、祝福 → 标准化需求
- 推荐:模板填充式
- 界面:展示10个生日模板供选择
用户输入:"用赛博朋克风格重新演绎《清明上河图》,镜头从河流推进到街市"
↓ AI分析
- 关键词:风格、镜头运动 → 复杂定制需求
- 推荐:对话式 + 参数面板
- 界面:生成初稿后展开运动控制面板
案例:Notion AI根据输入长度和复杂度,决定是直接返回结果还是打开编辑器
模式C:无缝模式切换(Seamless Mode Switching)
设计原则:用户可以在同一项目中随时切换交互方式,数据无损互通
实现方式:
·对话式生成的视频 → 一键切换到时间轴编辑
·工作流节点 → 右键"转为对话式调整"
·参数面板的设置 → 自动同步到对话历史
案例:Figma的"手动绘制 ⇄ 自动布局 ⇄ AI生成" 三者可随时切换
3. 技术突破带来的交互革命
① 意图理解的飞跃
过去:用户必须学习工具的"语言"(参数、节点、命令)
现在:工具开始理解用户的"语言"(自然描述、示例、反馈)
实例对比:
| 传统方式 | AI辅助方式 |
| 调整"色温" "饱和度" "对比度"参数 | 描述"让画面更温暖一些" |
| 设置关键帧+缓动曲线 | 说"镜头缓慢推进,末尾加速" |
| 选择滤镜+调透明度 | 上传参考图"做成这种风格" |
技术支撑:多模态大模型(如GPT-4V、Gemini)可以理解图像+文本组合意图
② 上下文记忆与学习
当前进展:工具开始记住用户的历史偏好和操作习惯
应用场景:
·风格记忆:用户连续生成5个"赛博朋克风"视频后,工具自动将该风格设为默认
·流程记忆:用户每次都执行"去水印→调色→加字幕",工具提示"创建自动化流程?"
·错误预防:检测到用户即将覆盖未保存的项目,提前警告
技术支撑:个性化推荐算法 + 用户行为序列分析
③ 智能交互路由
未来愿景:AI自动识别需求复杂度,推荐最优交互路径
工作原理:
用户:"我要做个视频"
↓
AI分析维度:
- 描述详细程度:8/10 → 意图明确
- 专业术语密度:2/10 → 非专业用户
- 定制化需求:6/10 → 中度定制
↓
推荐方案:对话式画布 + 参数微调面板
预计时间:15分钟
案例探索:Adobe Firefly已在尝试"快速模式/精准模式"的自动切换
4. 未来三年的关键趋势预测
趋势1:对话式将成为所有工具的"入口层"
即使是专业级工具(如DaVinci Resolve、Houdini),也会增加自然语言助手作为新手友好的入口,再逐步引导到传统界面。
类比:就像现在的编程,可以用GitHub Copilot对话生成代码,也可以直接写代码,两者并存。
趋势2:"意图→结果"的黑箱化与"过程→结果"的透明化并存
两种用户诉求:
·效率型用户:"我不在乎怎么做的,只要结果好" → 黑箱化的一键智能体
·创作型用户:"我需要理解每一步,才能优化" → 透明化的工作流画布
未来工具会明确区分这两种模式,而非试图用一种交互满足所有人。
趋势3:从"工具适应人"到"工具理解人"
终极目标:工具不再要求用户学习"正确的使用方式",而是自动适应每个用户的思维模式。
实现路径:
·第一阶段(当前):提供多种交互模式供用户选择
·第二阶段(1-2年):AI观察用户习惯,自动调整界面布局和推荐功能
·第三阶段(3-5年):每个用户看到的工具界面都是定制化的,像是专门为TA设计的
技术基础:强化学习 + 个性化UI生成
5. 对创作者的启示
短期建议(现在):
·不要局限于单一工具,学会根据项目需求组合使用
·优先掌握"对话式"交互,这是未来的通用技能
·保持对新工具的关注,交互范式每6个月就会迭代
长期思考(未来):
·核心竞争力将从"会用工具"转向"会提需求"和"会审美判断"
·工具的学习曲线会越来越平滑,但创意的门槛永远存在
·最好的创作者将是那些既懂AI能力边界,又保持人类独特视角的人
终极问题:当AI工具可以理解任何表达方式时,创作者的价值在哪里?
答案:在于提出值得创作的问题,在于对结果的品味判断,在于人类独有的情感共鸣。
四、实战案例:10分钟短剧如何拆解成40个15秒连续视频
案例背景
项目需求:将一个10分钟的都市爱情短剧剧本,拆解成40集15秒的竖屏短视频,用于抖音/快手连载发布
剧本特点:
·总时长:10分钟(600秒)
·分集数:40集 × 15秒
·场景数:12个场景(咖啡厅、办公室、街道、公寓等)
·角色数:男女主角 + 3个配角
·视觉风格:现代都市,电影感调色
方案A:工作流式画布(以Tapnow为例)
操作流程:
第一步:搭建主工作流(预计2小时)
[剧本输入节点]
↓
[AI分镜拆解节点] → 配置:按15秒单位拆分,保留情节连贯性
↓
[角色一致性节点] → 上传男女主角参考图,锁定面部特征
↓
[场景模板库] → 预设12个场景的lighting/摄影参数
↓
[视频生成节点] → 并行生成40个视频片段
↓
[质量检查节点] → AI检测面部崩坏、穿帮镜头
↓
[字幕嵌入节点] → 批量添加对白字幕
↓
[导出节点] → 统一规格:1080×1920,H.264编码
第二步:执行生成(预计6小时)
·点击"运行工作流",系统自动执行所有节点
·生成过程可视化显示进度
·出现问题的节点会标红,可单独重跑
第三步:人工审核与微调(预计3小时)
·查看40个视频缩略图
·发现第12、27集角色面部不一致 → 在对应节点调整"相似度阈值"参数
·重新生成问题片段
适用场景:
✅ 需要批量生产同类型视频(如连续剧、系列广告)
✅ 有技术能力搭建和维护工作流
✅ 追求可复用性,未来还要做第二季、第三季
总耗时:11小时(但工作流可复用,做第二季只需3小时)
方案B:对话式画布(以即梦为例)
操作流程:
第一轮对话(建立全局设定)
用户:"我有一个10分钟的都市爱情短剧剧本,需要拆解成40集15秒的竖屏视频。
男主:28岁,商务休闲风,成熟稳重。
女主:25岁,职场丽人风,活泼灵动。
整体风格:电影质感,暖色调。"
AI:"收到!我会为您:
1. 自动拆解剧本为40个15秒片段
2. 确保角色视觉一致性
3. 保持电影级画面质感
请上传完整剧本文件。"
第二轮对话(生成初稿)
用户:[上传剧本.docx]
AI:"已完成拆解,检测到12个场景。正在生成前5集预览...
[3分钟后]
预览已生成,请查看是否符合预期。"
用户:"第3集的咖啡厅场景太暗了,需要明亮温馨的感觉。"
AI:"明白,我会调整咖啡厅场景的照明为'自然光+暖色吊灯',重新生成第3集..."
第三轮对话(批量生成)
用户:"预览满意,生成全部40集。"
AI:"开始批量生成,预计需要40分钟。
进度:[████████░░] 85% (34/40)
预计完成时间:18:45"
第四轮对话(修正问题)
用户:"第18集和第19集之间不连贯,女主角突然换了衣服。"
AI:"检测到服装连续性问题。已重新生成第19集,确保与第18集服装一致。"
适用场景:
✅ 不想学习复杂工具,希望用自然语言控制
✅ 项目一次性,不需要高度复用
✅ 能接受10-15%的片段需要返工
总耗时:5小时(含等待生成时间)
方案C:一键生成智能体(以纳米AI为例)
操作流程:
步骤1:选择智能体模板
·在智能体市场搜索"短剧连载生成器"
·选择"都市爱情短剧40集生成"模板
步骤2:填写配置表单
[剧本上传] → 上传.docx文件
[集数设置] → 40集
[单集时长] → 15秒
[视频比例] → 竖屏 9:16
[风格选择] → 下拉菜单选择"现代都市·电影质感"
[角色设定] →
- 男主关键词:成熟、商务、稳重
- 女主关键词:职场、活泼、甜美
步骤3:点击"一键生成"
·系统自动执行:剧本拆解 → 分镜设计 → 视频生成 → 字幕嵌入
·全程无需干预
步骤4:下载成品
·1小时后收到通知:"您的40集短剧已生成完毕"
·打包下载所有视频文件
适用场景:
✅ 零技术基础,追求极致效率
✅ 对个性化要求不高,接受标准化风格
✅ 预算充足(智能体通常按任务收费)
总耗时:1.5小时(但个性化空间最小)
方案D:脚本编辑器模式(以Runway为例)
操作流程:
第一阶段:逐集生成初稿(预计4小时)
对每一集执行:
1.输入提示词:
第1集:咖啡厅内景,女主角坐在窗边看书,阳光洒在脸上。镜头:中景推进特写。时长:15秒。风格:电影质感,暖色调。
2.点击"生成视频"
3.等待2-3分钟,获得初稿
第二阶段:批量调参优化(预计3小时)
对不满意的片段进行微调:
·镜头运动调整:使用Motion Brush工具绘制运动轨迹
·风格一致性:在参数面板调整"色温""饱和度"确保40集色调统一
·角色一致性:上传角色参考图,使用"角色锁定"功能
第三阶段:导出与后期(预计2小时)
·批量导出40个视频文件
·使用剪映批量添加片头片尾、背景音乐
适用场景:
✅ 有一定视频制作经验
✅ 对每一集的画面有明确想法
✅ 愿意投入时间打磨细节
总耗时:9小时
方案E:序列化多模态输入(以Sora 2 Storyboard为例)
操作流程:
第一步:绘制分镜脚本(预计3小时)
使用Midjourney或手绘,创建40张分镜图:
第1集分镜:咖啡厅外景,暖色调,下午阳光
第2集分镜:女主角坐在窗边,捧着书,侧脸特写
第3集分镜:男主角推门进入,景深虚化
...
第40集分镜:两人在夕阳下牵手剪影
关键设计原则:
·角色造型保持一致(同一套参考图生成所有分镜)
·场景视角标注清晰(俯拍/平视/仰拍)
·色调情绪统一规划(前20集明快,后20集深沉)
第二步:上传到Sora 2 Storyboard(预计30分钟)
操作界面:
┌─────────────────────────────────────┐
│ [分镜1] [分镜2] [分镜3] ... [分镜40] │ ← 时间轴
├─────────────────────────────────────┤
│ 分镜1描述框: │
│ "咖啡厅外景,黄金时段,暖色调, │
│ 镜头从街道缓慢推向玻璃窗,15秒" │
├─────────────────────────────────────┤
│ [角色锁定] 男主参考图:[uploaded.jpg] │
│ [角色锁定] 女主参考图:[uploaded.jpg] │
└─────────────────────────────────────┘
第三步:批量生成与调优(预计2小时)
·点击"生成所有镜头"
·AI理解分镜序列的叙事逻辑,自动处理:
o镜头间的场景转换(淡入淡出/切换)
o角色外貌一致性(服装、发型、表情风格)
o情绪递进(从相遇的羞涩到结局的甜蜜)
第四步:精修问题片段(预计1.5小时)
发现问题:第12集男主角的西装颜色变了
↓
解决方案:
- 重新上传该分镜,强化服装描述:"深蓝色西装,白衬衫"
- 勾选"参考第8集的角色外观"
- 单独重新生成第12集
核心优势:
1. 叙事连贯性
·AI理解40个分镜是一个完整故事,而非40个独立任务
·自动维护角色关系(如两人从陌生到亲密的肢体语言变化)
2. 视觉一致性
·无需每次输入角色描述,系统记住"男主是谁"
·光线、色调在同场景内自动保持统一
3. 迭代效率
·不满意某一集?只需调整对应分镜,无需重跑全流程
·可以先做"低保真预览"(快速生成低质量版本),确认叙事后再高清渲染
适用场景:
✅ 有基础分镜绘制能力(或会用Midjourney)
✅ 需要多镜头连续叙事的项目(短片、广告、MV)
✅ 对视觉一致性要求高(角色、场景不能"穿帮")
✅ 愿意在前期分镜阶段投入时间
与其他方案的差异:
·vs 工作流画布:不需要学节点逻辑,用可视化分镜代替抽象配置
·vs 对话式:通过图片序列表达,比纯文字更精确
·vs 一键智能体:保留了分镜级的控制力,但比工作流简单
总耗时:7小时(其中3小时是绘制分镜,可复用于真人拍摄)
方案F:模板填充式(以剪映为例)
限制说明:剪映AI模板通常适合单条视频,不太适合40集连续剧场景。但如果降低要求,可以这样操作:
妥协方案:使用"AI成片"功能
步骤1:准备素材
·提前用Midjourney生成40张关键帧静态图
·录制或下载旁白音频
步骤2:批量套用模板
·选择"都市风短视频"模板
·逐集导入关键帧图+音频
·AI自动生成动态效果、转场、字幕
适用场景:
✅ 接受"图片轮播+动效"的简化形式(而非真正的AI视频生成)
✅ 预算极低,主要靠文案和创意取胜
总耗时:6小时(但视频质感大幅下降)
方案对比总结
| 方案 | 总耗时 | 质量控制 | 个性化 | 可复用性 | 成本 | 推荐指数 |
| 工作流画布 | 11小时(首次) 3小时(复用) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 低(订阅费) | ⭐⭐⭐⭐⭐ 适合系列化生产 |
| 对话式画布 | 5小时 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 中(按次收费) | ⭐⭐⭐⭐ 适合一次性项目 |
| 一键智能体 | 1.5小时 | ⭐⭐⭐ | ⭐⭐ | ⭐ | 高(任务打包费) | ⭐⭐⭐ 适合快速测试 |
| 脚本编辑器 | 9小时 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | 中 | ⭐⭐⭐⭐ 适合有经验创作者 |
| 序列化多模态输入 | 3小时 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 中 | ⭐⭐⭐⭐ 适合擅长分镜设计创作者 |
| 模板填充 | 6小时 | ⭐⭐ | ⭐ | ⭐⭐ | 低 | ⭐⭐ 仅限低预算 |
实战建议
如果你是MCN机构,要做多季短剧 → 选择工作流画布,前期投入时间搭建,后期收益巨大
如果你是个人创作者,首次尝试短剧 → 选择对话式画布,平衡效率与质量
如果你要快速验证剧本反响→ 选择一键智能体,1小时出成品测试市场
如果你是专业导演/摄影师→ 选择脚本编辑器,保留艺术控制力
结语
AI视频创作工具的交互革命,本质上是在不断降低创作门槛的同时,保留专业创作者所需的控制力。没有绝对最好的交互模式,只有最适合当前需求和能力的选择。
随着AI能力的提升,我们可能会看到"意图理解型交互"的出现——用户只需表达"我想要什么效果",AI自动选择最优的生成路径和参数组合,真正实现"所想即所得"的创作体验。
那时,工具的界限将进一步模糊,创作者可以将全部精力投入到创意本身,而非与工具的博弈。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。