



DeepSeek发布双模型有什么意义?

在ChatGPT迎来发布三周年之际,AI领域再次迎来重磅消息——DeepSeek公司一举推出两款全新模型:DeepSeek-V3.2与DeepSeek-V3.2-Speciale,为AI技术发展注入强劲动力!
一模型亮点速览
DeepSeek-V3.2:平衡实用,性能卓越
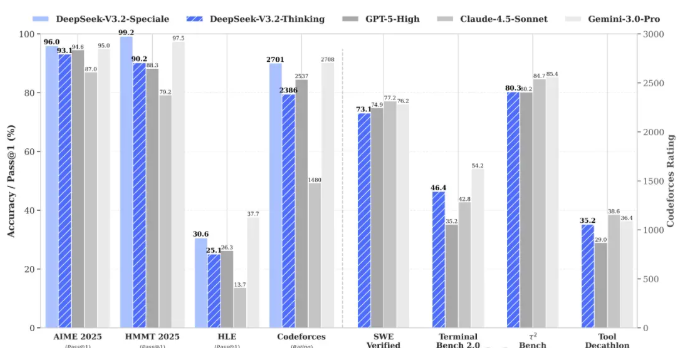
DeepSeek-V3.2聚焦于平衡推理能力与输出长度,专为日常问答、通用Agent任务及真实应用场景下的工具调用量身打造。该模型在推理能力上比肩GPT-5,虽略逊于Gemini-3.0-Pro,但在实用性和效率上实现了显著突破。
- 推理能力:达到GPT-5水平,适用于复杂逻辑推理任务。
- 输出优化:相比Kimi-K2-Thinking,大幅缩短输出长度,减少用户等待时间。
- 工具调用:支持思考/非思考双模式工具调用,首个实现“思考融入工具调用”的模型。
- 泛化能力:基于1800+环境、85000+复杂指令的大规模Agent训练数据,泛化能力出众。
DeepSeek官微宣称,V3.2模型在Agent评测中达到了当前开源模型的最高水平,展现了强大的实用潜力。
DeepSeek-V3.2-Speciale:极致推理,挑战极限
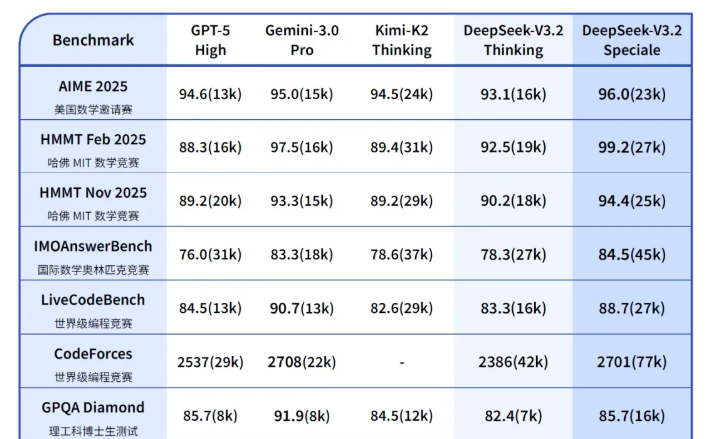
DeepSeek-V3.2-Speciale作为V3.2的长思考增强版,融合了DeepSeek-Math-V2的定理证明能力,主打极致推理。该模型在指令跟随、数学证明、逻辑验证方面表现卓越,一举斩获IMO 2025、CMO 2025、ICPC World Finals 2025、IOI 2025金牌,ICPC成绩达到人类选手第二,IOI成绩位列人类选手第十。
- 极致推理:推理基准性能媲美Gemini-3.0-Pro。
- 专项优化:针对高度复杂数学推理、编程竞赛、学术研究类任务进行优化。
- 使用限制:目前未针对日常对话与写作做专项优化,仅供研究使用,不支持工具调用。
二技术架构创新
DSA机制:降低计算复杂度,提升推理效率
DeepSeek-V3.2最大的架构创新在于引入了DSA(DeepSeek Sparse Attention)机制。该机制通过闪电索引器(lightning indexer)和细粒度token选择(fine-grained token selection)机制,将计算复杂度从传统的O(L²)降低至O(L·k),其中k远小于L,显著提升了模型在长上下文任务中的推理效率。
- 闪电索引器:快速计算查询token和历史token之间的相关性分数,选择top-k个最相关的token进行注意力计算。
- 细粒度token选择:通过ReLU激活函数提升吞吐量,确保高效计算。
实测数据显示,在128k长度的序列上,DeepSeek-V3.2的推理成本比V3.1-Terminus降低了好几倍,H800集群上的测试显示,预填充阶段每百万token的成本从0.7美元降至0.2美元左右,解码阶段从2.4美元降至0.8美元。
强化学习训练:计算资源投入超预训练10%
DeepSeek团队在强化学习训练上下了大力气,计算预算超过了预训练成本的10%,这在开源模型中极为罕见。通过稳定、可扩展的RL协议,解锁了模型的先进能力。
- 无偏KL估计:修正原始K3估计器,消除系统性误差,确保训练稳定。
- 离线序列掩码策略:通过计算数据采样策略和当前策略之间的KL散度,避免负样本序列干扰训练。
- Keep Routing操作:针对MoE模型设计,确保参数优化的一致性。
三Agent任务突破与数据合成管线
Agent任务突破:推理与工具使用能力并重
DeepSeek-V3.2团队找到了让模型同时具备推理和工具使用能力的方法。通过设计新的管理机制,只有在引入新的用户消息时才丢弃历史推理内容,保留工具调用历史和结果,提高了任务处理的连贯性和效率。
自动环境合成pipeline:生成海量复杂任务数据
团队开发了一个自动环境合成pipeline,生成了1827个任务导向的环境和85000个复杂提示,涵盖了旅行规划、编程竞赛、软件问题解决等多个领域。这些数据通过RL训练,显著提升了模型在复杂任务上的表现。
- 旅行规划:模型需在满足各种约束条件下规划行程,展现了强大的逻辑推理和规划能力。
- 代码Agent:从GitHub挖掘数百万个issue-PR对,搭建数万个可执行的软件问题解决环境,支持多种编程语言。
- 搜索Agent:采用多Agentpipeline生成训练数据,提高数据质量和多样性。
四评测结果与未来展望
评测结果:超越现有开源模型
评测结果显示,DeepSeek-V3.2在SWE-Verified上达到73.1%的解决率,在Terminal Bench 2.0上准确率46.4%,均大幅超越现有开源模型。在MCP-Universe和Tool-Decathlon等工具使用基准测试上,也展现出了接近闭源模型的性能。
未来展望:持续优化,迎接挑战
尽管DeepSeek-V3.2在多个方面取得了显著进展,但研究人员也坦诚地指出了模型的局限性。由于总训练FLOPs较少,模型的世界知识广度仍落后于领先的闭源模型。同时,Token效率也是一大挑战,需要生成更长的轨迹才能达到Gemini-3.0-Pro的输出质量。
然而,DeepSeek团队已经明确表示,这些将是未来版本的改进方向。我们有理由相信,在不久的将来,DeepSeek将带来更多惊喜,推动AI技术不断向前发展!
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。