



为什么最强AI也数不清手指?多模态模型的致命缺陷
一道送分题,让全球AI集体翻车
我给你出道题:这张图片里有几根手指?

如果你数出了6根,恭喜你,智商已经超越地球上所有的AI。
不信?我拿这张图片问了一圈:ChatGPT、DeepSeek、豆包……这些大名鼎鼎的AI模型,几乎全都信誓旦旦地回答:5根手指。
而且它们还会煞有介事地给你分析一番:“从左到右依次是大拇指、食指、中指、无名指、小拇指”,一副专家鉴定的架势。
更离谱的还在后面。
当我和ChatGPT讨论完"你为什么数错了"之后,再给它发一张正常的5根手指照片,它居然回答:6根手指。
这是什么操作?难道AI也会"一朝被蛇咬,十年怕井绳"?
后来我发现,原来是ChatGPT的记忆功能在作祟——它把之前的错误当成了"经验教训",结果越改越离谱。关掉记忆功能后,它才恢复正常。
但这暴露了一个更严重的问题:AI不仅数不清手指,还极容易被一点点上下文信息干扰。
GPT-5也没能幸免
你可能会说:这些都是老模型,最新的GPT-5总该行了吧?
我专门切了个账号测试了一下,结果——GPT-5居然答对了!
"哈!不愧是地表最强模型!"我心想。
然后我又发了张8根手指的图片……它又对了。
再发一张正常5根手指的图片……还是对的!
等等,这剧情不对啊。难道GPT-5真的解决了这个问题?
仔细一想,可能是因为"AI数不清手指"这个话题最近讨论太多,相关数据被过度训练了。这就像考前刷题刷到了原题——不是真懂,只是背过答案。
为了验证,我换了些不常见的手部姿势,GPT-5立刻露馅了。
结论:从ChatGPT到DeepSeek,从豆包到GPT-5,没有一个能稳定通过"数手指"这道人类幼儿园水平的题目。
这背后一定有某种底层机制的问题。
揭秘:AI是如何"看"图片的?
要理解为什么AI数不清手指,我们得先搞清楚:AI到底是怎么处理图片的?
第一步:拆解多模态模型
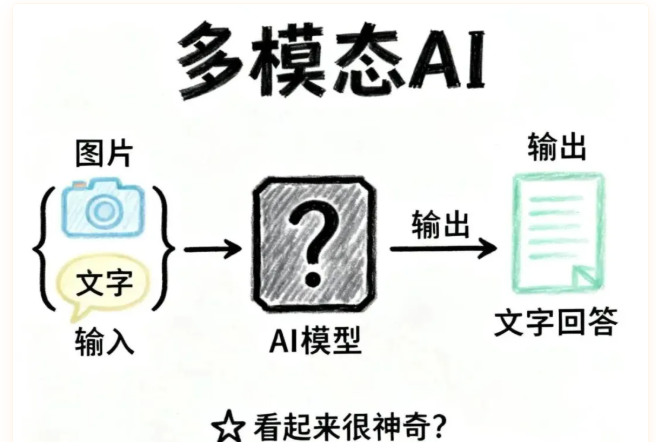
所谓"多模态模型",就是能同时处理不同类型信息(文字、图片、声音等)的AI。
比如你给AI发了张照片+一段文字问题,它能理解图片内容并用文字回答你。看起来很神奇,但本质上,这个过程可以简化成:
输入: 图片 + 文字
输出: 文字
关键问题来了:图片和文字是完全不同的东西,AI怎么把它们放在一起处理?
第二步:把一切变成向量
AI的解决方案很简单粗暴:把所有东西都转换成向量(一串数字),然后统一处理。
文字处理:
- 先把句子拆成词(tokenization)
- 每个词转换成一个向量
- 喂给大语言模型,输出概率分布
- 一个词一个词地生成回复
这个流程在大语言模型里已经非常成熟了。
图片处理:
- 用CNN或ViT等图像编码器
- 把图片转换成一组向量
- 每个向量代表图片的某种特征
看起来很美好:文字有向量,图片也有向量,直接拼起来不就行了?
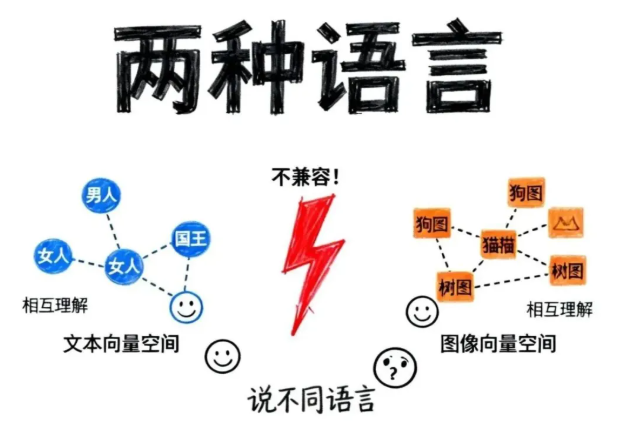
但问题是:这两种向量根本"说不同的语言"!
第三步:模态对齐——让向量"学同一种语言"
在大语言模型的向量空间里,"男人"和"女人"的向量是相似的,因为它们语义相关。
但图像编码器生成的向量,是在完全不同的向量空间里训练出来的。一张狗的照片转换成的向量,可能跟"狗"这个词的向量八竿子打不着。
这就像把中文和英文直接拼在一起——AI看着一脸懵逼。
所以必须有一个步骤,叫做“模态对齐”(Modality Alignment):让图片向量和文字向量在同一个语义空间里对应起来。
怎么做呢?
CLIP:400万张图教会AI"看图说话"
OpenAI提出的CLIP模型,用了一个巧妙的方法:
1. 收集海量数据
- 从网上爬取4亿对"图片+文字描述"
- 比如一张狗的照片配文字"一只金毛在草地上奔跑"
2. 分别编码
- 图片通过图像编码器→图像向量
- 文字通过文本编码器→文本向量
3. 对比学习(Contrastive Learning)
- 计算所有图像向量和文本向量的相似度
- 匹配的图文对(正样本):让它们的向量尽可能相似
- 不匹配的图文对(负样本):让它们的向量尽可能不同
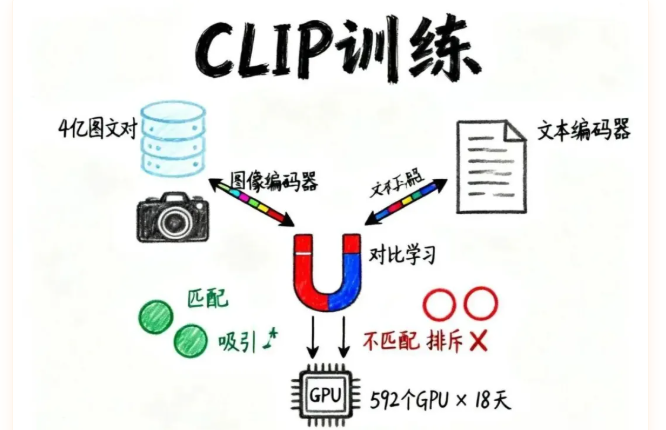
4. 海量训练
- 用592个V100 GPU
- 训练18天
- 完成模态对齐
训练完成后,一张狗的照片转换成的向量,就会和"狗"这个词的向量非常接近了。
于是,图片和文字终于可以"对话"了。
问题的根源:从图像到文字的"翻译损失"
现在我们可以回答开头的问题了:为什么AI数不清手指?
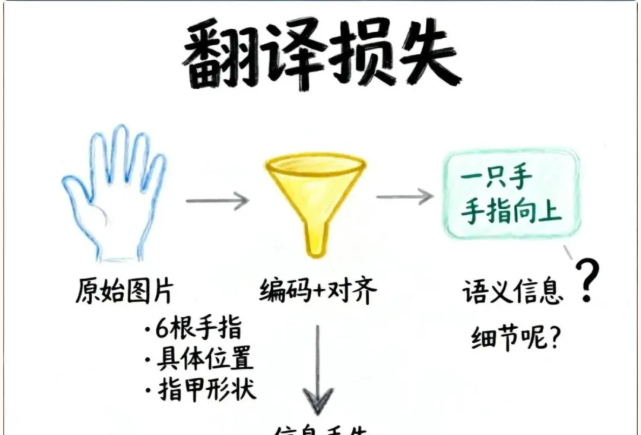
核心原因:多模态模型处理图片的方式,本质上是先把图片"翻译"成文字描述,然后基于文字进行推理。
经过图像编码器和模态对齐后,图片保留的只是语义级别的信息——“这是一只手”、“手指朝上”、“皮肤是肉色”……
但视觉细节,比如"到底有几根手指"、“手指的具体位置”、“指甲的形状”,这些信息在转换过程中就丢失了。
这就像你用中文描述一幅画,然后让只懂英文的人根据你的英文翻译来回答画的细节——翻译过程中必然有信息损耗。
一个小游戏:你能描述清楚吗?
为了让你亲身体验这种困难,我们来做个实验。
这里有一张非常简单的图片(比如一个几何图形组合)。
请你用文字描述这张图片,任意多字都行。
描述完之后,我问你几个问题:
- 左上角的圆圈和右下角的三角形,哪个面积更大?
- 正方形的边长是圆圈直径的几倍?
- 三角形的顶点和圆心的连线,与水平线的夹角是多少度?
你会发现:基于你的文字描述,这些问题根本答不出来!
这就是AI面临的困境——它被迫用文字描述来"看"图片,自然丢失了大量视觉细节。
为什么文本模型擅长推理,却不擅长数手指?
有意思的地方来了。
大语言模型在文字推理上极其强大:
- 总结归纳:提取长文档的核心观点
- 逻辑推理:根据前提推导结论
- 文字游戏:理解双关语、成语接龙
甚至在很多推理题上,AI的表现已经超过了人类。
但为什么一到"数手指"这种视觉任务,就立刻翻车?
答案很简单:因为大语言模型的训练基础是文本,而文本本身就是人类思维的"二次加工产品"。
想象一下:
- 你看到一只狗
- 你的大脑形成对狗的认知(视觉、听觉、触觉的综合感受)
- 你用语言描述:“一只金毛在草地上奔跑”
文字是第3步的产物,已经经过了大脑的抽象和总结。
AI基于海量文本训练,学会的是"人类如何用文字表达思维",而不是"人类如何直接感知世界"。
所以:
- ✅ 文字推理:AI很擅长,因为这就是它的训练基础
- ❌ 视觉细节:AI很弱,因为它只能通过"文字描述"间接理解图片

CLIP论文也承认了这个局限
在CLIP的论文里,研究者明确指出了这个问题:
即使用4亿图文对训练,CLIP在MNIST手写数字识别任务上的准确率,还不如最简单的逻辑回归模型。
MNIST是什么?就是识别0-9这10个手写数字,是深度学习领域的"Hello World"。
连这么简单的任务都做不好,说明这种"图像→文字→推理"的范式,天生就有缺陷。
能解决吗?技术上可以,但……
你可能会问:既然知道问题在哪儿,能不能针对性地解决?
技术上完全可以。
比如用YOLO这种目标检测模型:
- 准确识别手指
- 精确标注每根手指的位置
- 轻松数清有几根
但这只是解决了单一任务。
真正的挑战是:如何把这种能力整合进通用的多模态模型?
目前的多模态模型追求的是"泛化能力"——能处理各种图片、回答各种问题。如果要让它像YOLO一样精确识别视觉细节,就需要:
- 重新设计模型架构
- 收集更细粒度的训练数据
- 大幅增加计算成本
这是完全不同维度的工程挑战。
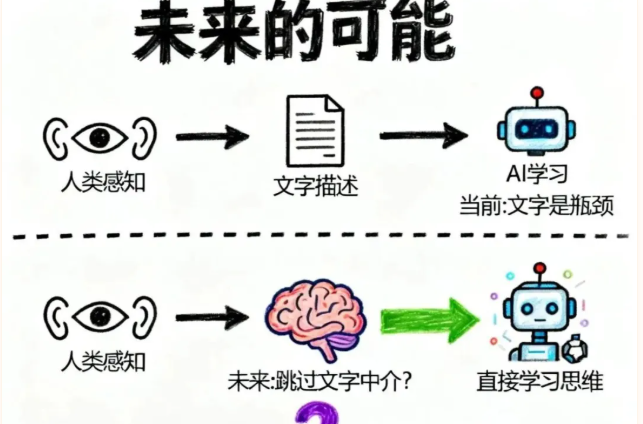
未来:基于"思维"而非"文本"的AI?
视频的最后,作者提出了一个脑洞大开的想法:
如果AI不再基于文本训练,而是基于人类思维训练,会怎样?
这个想法听起来科幻,但值得思考。
目前的范式:
- 人类感知世界
- 人类用文字描述感知
- AI基于文字学习
这个流程里,文字是中介,也是瓶颈。
如果能跳过这个中介:
- 人类感知世界
- AI直接学习人类的感知过程
- 形成"多模态原生"的理解
那么图片、声音、触觉……所有感知信息都在同一个"思维空间"里表示,不再需要"翻译"。
但问题是:人类思维到底是什么?
这又回到了哲学和神经科学的根本问题。我们用文本模型去理解人类思维,本身就是循环论证。
或许这正是AI发展的下一个大瓶颈。
结语:保持平衡的视角
通过"AI数不清手指"这个小问题,我们揭开了多模态模型的底层逻辑:
核心机制:
- 图像→向量(编码)
- 文本→向量(编码)
- 模态对齐(让两种向量"说同一种语言")
- 基于文本语义空间进行推理
固有局限:
- 视觉细节在转换中丢失
- 本质上是"图像→文字→推理"的间接路径
- 擅长语义理解,不擅长精确识别
这并不意味着AI很"蠢",而是说明:不同任务需要不同的技术方案。
AI的长处:
- ✅ 文本总结与生成
- ✅ 逻辑推理与规划
- ✅ 模式识别与预测
- ✅ 大规模信息处理
AI的短板:
- ❌ 视觉细节识别
- ❌ 物理常识推理
- ❌ 长期记忆与一致性
- ❌ 真正的"理解"
认识到这些,我们才能更好地使用AI,而不是盲目崇拜或全盘否定。
当你看到AI考试得高分,不要以为人类要完蛋了;当你看到AI数不清手指,也不要觉得AI都是傻子。
技术有边界,认知有局限,这才是真实的世界。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。