



如何构建推理模型?AI推理型大语言模型(LLMs)的介绍
本文介绍了构建推理模型的四种主要方法,即我们如何为大语言模型(LLMs)赋予推理能力。希望这些内容能为你提供有价值的见解,帮助你在这一领域快速发展的文献和炒作中理清方向。
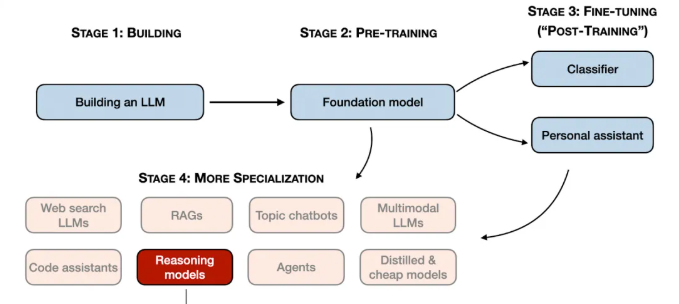
2024年,大语言模型领域呈现出日益明显的专业化趋势。除了预训练和微调之外,我们见证了各种专用应用的兴起,从检索增强生成(RAG)到代码助手等。我预计这一趋势将在2025年进一步加速,领域和应用场景特定的优化(即“专业化”)将受到更多重视。
推理模型的开发正是这些专业化方向之一。这意味着我们对大语言模型(LLMs)进行优化,使其在需要中间步骤才能解决的复杂任务上表现出色,例如解谜题、高阶数学问题和编程挑战等。然而,这种专业化并不会取代其他类型的LLM应用,因为将一个通用LLM转变为推理模型也会带来某些弊端,我将在后文加以讨论。
为了让你快速了解下文内容,本文将:
- 阐释“推理模型”的含义
- 探讨推理模型的优势与劣势
- 概述 DeepSeek R1 背后的技术方法
- 介绍构建和改进推理模型的四种主要途径
- 分享在 DeepSeek V3 和 R1 发布之后对大语言模型格局的一些思考
- 提供在预算有限的情况下开发推理模型的实用建议
希望本文能在人工智能今年持续高速发展的背景下,为你带来切实的帮助!
我们如何定义“推理模型”?
如果你从事人工智能(或更广义的机器学习)领域,你很可能已经习惯了那些模糊且充满争议的术语定义。“推理模型”也不例外。最终,总会有某篇论文对它做出正式定义,但很快又会在下一篇论文中被重新诠释,如此往复。
在本文中,我将“推理”定义为:回答那些需要复杂、多步骤生成并包含中间推理过程的问题。例如,“中国的首都是哪里?”这类事实型问答并不涉及推理;而像“一列火车以每小时60英里的速度行驶了3小时,它行驶了多远?”这样的问题则需要一定的简单推理——比如,必须先识别出距离、速度和时间之间的关系,才能得出答案。

大多数现代大语言模型(LLMs)都具备基本的推理能力,能够回答诸如“一列火车以每小时60英里的速度行驶了3小时,它行驶了多远?”这类问题。因此,如今当我们提到“推理模型”时,通常指的是那些在更复杂的推理任务上表现卓越的大语言模型,例如解答谜题、脑筋急转弯以及数学证明等。
此外,目前大多数被冠以“推理模型”之名的大语言模型,其输出通常包含一个“思考”或“思维”过程。至于大语言模型是否真的在“思考”,以及如何“思考”,则是另一个值得探讨的话题。
推理模型中的中间步骤可以以两种方式呈现:
第一种是明确地将其包含在模型的输出中,如前文图示所示;
第二种是一些推理型大语言模型(例如 OpenAI 的 o1)会在内部进行多轮迭代,生成中间步骤,但这些步骤并不会展示给用户。
我们何时应该使用推理模型?
在明确了推理模型的定义之后,我们可以进入更有趣的部分:如何构建和改进用于推理任务的大语言模型(LLMs)。然而,在深入技术细节之前,我们首先需要思考一个关键问题:究竟在什么情况下才真正需要推理模型?
我们什么时候需要推理模型?推理模型专为处理复杂任务而设计,例如解谜题、高阶数学问题以及具有挑战性的编程任务。但对于更简单的任务,如文本摘要、翻译或基于知识的事实型问答,则并不需要推理模型。事实上,对所有任务都使用推理模型可能既低效又昂贵。例如,推理模型通常使用成本更高、输出更冗长,有时还会因“过度思考”而更容易出错。这里同样适用一条简单原则:为任务选择合适的工具(或合适类型的大语言模型)。
下图总结了推理模型的主要优势与局限性。

简要了解 DeepSeek 的训练流程
在下一节讨论构建和改进推理模型的四种主要方法之前,我想先简要概述一下 DeepSeek R1 的训练流程,该流程源自《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》。这份报告不仅是一个有趣的案例研究,也为开发推理型大语言模型提供了可借鉴的蓝图。
需要注意的是,DeepSeek 并未只发布单一的 R1 推理模型,而是推出了三个不同的变体:DeepSeek-R1-Zero、DeepSeek-R1 和 DeepSeek-R1-Distill。
根据技术报告中的描述,我将这些模型的开发流程总结在下图中。
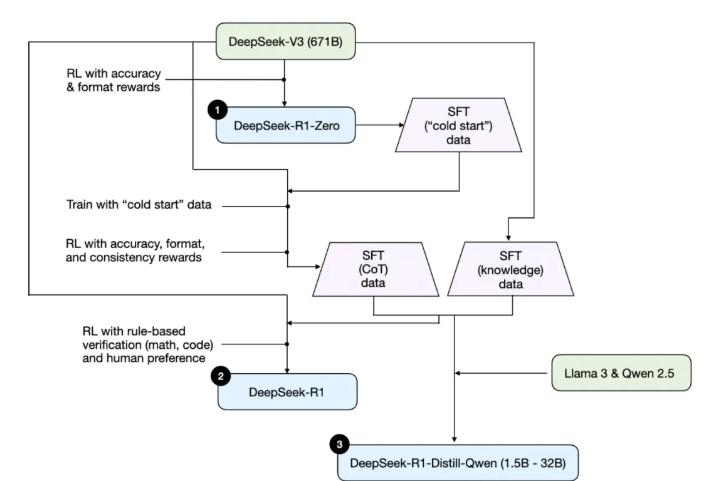
接下来,我们简要回顾一下上图所示的流程。更多细节将在下一节展开,届时我们将讨论构建和改进推理模型的四种主要方法。
(1)DeepSeek-R1-Zero:该模型基于 2024 年 12 月发布的 671B 参数预训练基础模型 DeepSeek-V3。研究团队使用强化学习(RL)对其进行训练,并采用了两种类型的奖励信号。这种方法被称为“冷启动”(cold start)训练,因为它跳过了通常在人类反馈强化学习(RLHF)中包含的监督微调(SFT)步骤。
(2)DeepSeek-R1:这是 DeepSeek 的旗舰推理模型,建立在 DeepSeek-R1-Zero 的基础上。团队通过额外的 SFT 阶段和进一步的 RL 训练对其进行了优化,从而在“冷启动”的 R1-Zero 模型之上实现了性能提升。
(3)DeepSeek-R1-Distill*:利用前几步生成的 SFT 数据,DeepSeek 团队对 Qwen 和 Llama 系列模型进行了微调,以增强它们的推理能力。虽然这一过程并非传统意义上的知识蒸馏,但它确实使用了更大的 DeepSeek-R1(671B)模型的输出,来训练更小的模型(包括 Llama 8B 和 70B,以及 Qwen 1.5B–30B)。
构建和改进推理模型的四大主要方法
在本节中,我将概述当前用于提升大语言模型(LLM)推理能力、并构建专用推理模型(如 DeepSeek-R1、OpenAI 的 o1 和 o3 等)的关键技术。
注:o1 和 o3 的具体实现细节在 OpenAI 之外尚不公开。但据传它们结合了推理阶段和训练阶段的多种技术。
1) 推理时扩展(Inference-time scaling)
提升 LLM 推理能力(或任何能力)的一种方式是推理时扩展。这一术语有多种含义,但在本文语境下,特指在推理过程中增加计算资源,以提高输出质量。
一个粗略的类比是:人类在面对复杂问题时,如果给予更多思考时间,通常能给出更好的答案。类似地,我们可以采用一些技术,促使 LLM 在生成答案时进行更多“思考”(尽管 LLM 是否真的“思考”是另一个话题)。
推理时扩展的一个直接方法是巧妙的提示工程(prompt engineering)。经典例子是思维链(Chain-of-Thought, CoT),即在输入提示中加入“请逐步思考”之类的引导语句。这会鼓励模型生成中间推理步骤,而不是直接跳到最终答案——对于更复杂的问题,这种做法通常(但并非总是)能带来更准确的结果。
(注意:对于像“中国首都是哪里?”这类简单的知识型问题,使用此类策略并无意义。这也是一条实用的经验法则:判断你的输入查询是否真正需要推理模型。)
前面提到的思维链(CoT)方法可被视为一种推理时扩展,因为它通过生成更多的输出 token 使推理过程变得更加“昂贵”(即计算开销更大)。
另一种推理时扩展的方法是采用投票和搜索策略。一个简单的例子是多数投票(majority voting):让大语言模型生成多个答案,然后通过多数投票选出最终答案。类似地,我们也可以使用束搜索(beam search)等其他搜索算法来生成更优的回答。
若想深入了解这些不同策略,我强烈推荐阅读论文《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters》
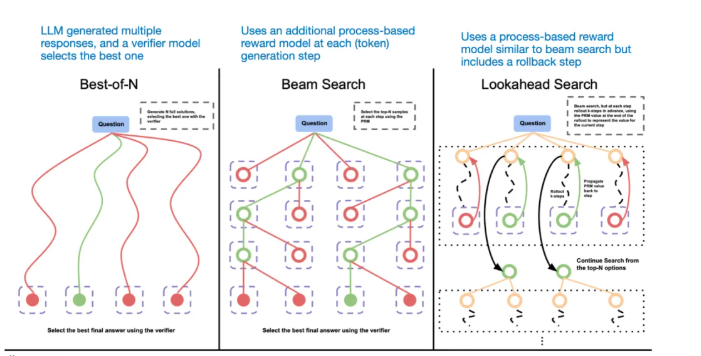
《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》将常见的推理时扩展方法(例如基于过程奖励模型(Process Reward Model)和基于蒙特卡洛树搜索(Monte Carlo Tree Search)的方法)归类为“未成功的尝试”。这表明,除了 R1 模型本身相比 V3 基础模型更倾向于生成更长的回答(这种倾向可视为一种隐式的推理时扩展)之外,DeepSeek 并未显式采用这些技术。
然而,显式的推理时扩展通常是在应用层(而非大语言模型内部)实现的,因此 DeepSeek 仍有可能在其应用程序中使用这类技术。
我推测 OpenAI 的 o1 和 o3 模型采用了推理时扩展技术,这也解释了为何它们的使用成本明显高于 GPT-4o 等模型。除了推理时扩展之外,o1 和 o3 很可能也使用了类似于 DeepSeek R1 的强化学习(RL)训练流程。关于强化学习的更多内容,将在接下来的两节中详细展开。
2) 纯强化学习(Pure Reinforcement Learning, RL)
《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》中让我个人印象最深的一点是:他们发现推理能力可以作为一种行为,从纯强化学习中自然涌现。下面我们来深入探讨这一发现的含义。
如前所述,DeepSeek 开发了三种 R1 模型。其中第一种是 DeepSeek-R1-Zero,它基于 DeepSeek-V3 基础模型构建——这是他们在 2024 年 12 月发布的一个标准预训练大语言模型。与典型的强化学习流程不同(通常会在 RL 之前先进行监督微调,即 SFT),DeepSeek-R1-Zero 完全仅通过强化学习进行训练,没有初始的 SFT 阶段,如下图所示。
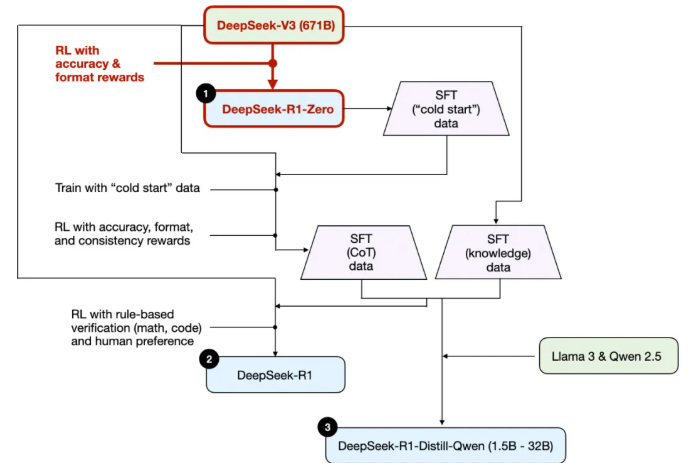
尽管如此,这种强化学习(RL)过程与常用的基于人类反馈的强化学习(RLHF)方法类似,后者通常用于对大语言模型(LLMs)进行偏好微调。然而,如前所述,DeepSeek-R1-Zero 的关键区别在于跳过了用于指令微调的监督微调(SFT),正因如此,他们称之为“纯”强化学习(“pure” RL)。(不过需要指出的是,大语言模型语境下的 RL 与传统强化学习存在显著差异,但这属于另一个话题了。)
在奖励机制方面,他们并未使用基于人类偏好训练的奖励模型,而是采用了两种类型的奖励:准确性奖励(accuracy reward)和格式奖励(format reward)。
- 准确性奖励
- 格式奖励
令人惊讶的是,仅凭这种方法,该大语言模型就发展出了基本的推理能力。研究人员观察到了一个“顿悟时刻”(“Aha!” moment)——尽管模型从未被明确训练去生成推理过程,它却开始在回答中自发地输出推理轨迹(reasoning traces),如下图所示。

尽管 R1-Zero 并非顶尖的推理模型,但它确实展现出了推理能力——如上图所示,它能够生成中间的“思考”步骤。这证实了仅通过纯强化学习(pure RL)来构建推理模型是可行的,而 DeepSeek 团队是首个展示(或至少公开发表)这一方法的研究团队。
3) 监督微调与强化学习(SFT + RL)
接下来,我们来看 DeepSeek 旗舰推理模型 DeepSeek-R1 的开发过程,该模型为构建推理模型提供了一个范本。它在 DeepSeek-R1-Zero 的基础上,进一步引入了额外的监督微调(SFT),以提升其推理性能。
需要注意的是,在标准的 RLHF(基于人类反馈的强化学习)流程中,通常都会在强化学习之前加入一个 SFT 阶段,这种做法其实相当普遍。OpenAI 的 o1 模型很可能也采用了类似的方法进行开发。
如上图所示,DeepSeek 团队使用 DeepSeek-R1-Zero 生成了他们称之为“冷启动”(cold-start)的监督微调(SFT)数据。这里的“冷启动”指的是:这些数据由 DeepSeek-R1-Zero 生成,而该模型本身从未接受过任何监督微调(SFT)数据的训练。
利用这批冷启动 SFT 数据,DeepSeek 首先对模型进行了指令微调(instruction fine-tuning),随后又进行了一轮强化学习(RL)。这一 RL 阶段沿用了 DeepSeek-R1-Zero 中使用的相同准确性奖励和格式奖励,但额外增加了一个一致性奖励(consistency reward),用于防止模型在单次回答中混用多种语言(即“语言混杂”现象)。
在完成该 RL 阶段后,团队又进行了一轮 SFT 数据收集。在此阶段,他们使用最新模型检查点生成了 60 万条思维链(Chain-of-Thought, CoT),同时另外使用 DeepSeek-V3 基础模型创建了 20 万条基于知识的 SFT 示例。
这总计 80 万条(60 万 + 20 万)SFT 样本随后被用于对 DeepSeek-V3 基础模型进行指令微调,并紧接着进行了最后一轮强化学习。在这一最终 RL 阶段,对于数学和编程类问题,他们继续采用基于规则的方法提供准确性奖励;而对于其他类型的问题,则使用了人类偏好标注作为奖励信号。总体而言,这一流程与标准的 RLHF 非常相似,主要区别在于:
- SFT 数据中包含(更多)思维链(CoT)示例;
- RL 阶段除了基于人类偏好的奖励外,还引入了可验证的奖励机制。
最终得到的 DeepSeek-R1 模型,得益于额外的 SFT 和 RL 训练阶段,在性能上相比 DeepSeek-R1-Zero 实现了显著提升
4) 纯监督微调(SFT)与蒸馏
到目前为止,我们已经介绍了构建和改进推理模型的三种关键方法:
- 推理时扩展
- 纯强化学习
- 监督微调 + 强化学习
那么,还剩下什么方法呢?答案是模型“蒸馏”(distillation)。
令人意外的是,DeepSeek 还发布了一系列通过他们称之为“蒸馏”的流程训练得到的小型模型。然而,在大语言模型(LLM)的语境下,“蒸馏”并不一定遵循深度学习中传统的知识蒸馏(knowledge distillation)方法。按照传统定义,知识蒸馏是指让一个较小的“学生”模型同时学习大型“教师”模型的输出 logits 和目标任务数据。
而在这里,“蒸馏”指的是:在由大型 LLM 生成的 SFT 数据集上,对更小的 LLM(例如 Llama 8B 和 70B,以及 Qwen 2.5 系列模型,参数规模从 0.5B 到 32B 不等)进行指令微调。具体而言,这些大型 LLM 包括 DeepSeek-V3 和 DeepSeek-R1 的一个中间检查点。事实上,用于此次蒸馏过程的 SFT 数据,正是前一节中描述的、用于训练 DeepSeek-R1 的同一数据集。
为清晰说明这一流程,我在下图中特别标出了蒸馏部分。
他们为什么要开发这些蒸馏模型呢?在我看来,主要有两个关键原因:
- 小型模型更高效。这意味着它们运行成本更低,同时也能在性能较低的硬件上运行,这对许多研究人员和像我这样的技术爱好者来说尤其具有吸引力。
- 纯监督微调(SFT)。这些蒸馏模型提供了一个有趣的基准案例,展示了仅依靠纯监督微调(不使用强化学习)能在多大程度上提升模型性能。
下表对比了这些蒸馏模型与其他主流模型、以及 DeepSeek-R1-Zero 和 DeepSeek-R1 的性能表现。
如我们所见,这些蒸馏模型的性能明显弱于 DeepSeek-R1,但令人惊讶的是,尽管它们的参数规模比 DeepSeek-R1-Zero 小几个数量级,其表现却显著优于后者。此外值得注意的是,这些模型与 o1-mini 的性能对比也相当出色(我怀疑 o1-mini 本身可能也是 o1 的一种类似蒸馏版本)。
在结束本节之前,还有一个有趣的对比值得一提。DeepSeek 团队测试了在 DeepSeek-R1-Zero 中观察到的“涌现式推理行为”是否也能出现在更小的模型中。为此,他们将 DeepSeek-R1-Zero 所采用的纯强化学习(pure RL)方法直接应用于 Qwen-32B 模型。
该实验的结果总结在下表中,其中 QwQ-32B-Preview 作为参照推理模型,是由 Qwen 团队基于 Qwen 2.5 32B 开发的(据我所知,其训练细节从未公开)。这一对比进一步揭示了一个关键问题:仅靠纯强化学习,是否也能在远小于 DeepSeek-R1-Zero 的模型中激发出推理能力?
有趣的是,实验结果表明,对于小型模型而言,蒸馏(即基于高质量推理数据的监督微调)。这支持了一种观点:仅靠强化学习(RL)可能不足以在这一规模的模型中激发出强大的推理能力,而使用高质量推理数据进行监督微调(SFT)在小型模型上可能是更有效的策略。
为了更全面地评估,表中若能包含以下两项额外对比会更有价值:
- 采用 SFT + RL 训练的 Qwen-32B,训练方式类似于 DeepSeek-R1 的开发流程。这将有助于判断:与纯 RL 或纯 SFT 相比,将 RL 与 SFT 结合究竟能带来多大程度的性能提升。
- 仅通过纯 SFT 微调的 DeepSeek-V3,其训练方式与蒸馏模型的构建过程类似。这样就能直接比较“RL + SFT”相较于“纯 SFT”到底有多大的优势。
结论
在本节中,我们探讨了构建和提升推理模型的四种不同策略:
- 推理时扩展(Inference-time scaling)无需额外训练,但会增加推理成本。随着用户数量或查询量的增长,大规模部署的成本将显著上升。尽管如此,对于已经较强的模型而言,这种方法仍是提升性能的“不二之选”。我强烈怀疑 OpenAI 的 o1 模型就采用了推理时扩展,这也解释了为何其每 token 的成本高于 DeepSeek-R1。
- 纯强化学习(Pure RL)在研究层面颇具启发性,因为它揭示了推理能力可以作为一种“涌现行为”自然产生。然而在实际模型开发中,RL + SFT 才是更优选择,能构建出更强的推理模型。我同样高度怀疑 o1 也采用了 RL + SFT 的训练方式。更具体地说,我认为 o1 可能基于一个比 DeepSeek-R1 更弱、更小的基础模型,但通过 RL + SFT 和推理时扩展进行了弥补。
- 如前所述,RL + SFT 是构建高性能推理模型的核心方法。DeepSeek-R1 为此提供了一个出色的范本,清晰展示了这一流程如何实现。
- 蒸馏(Distillation)是一种极具吸引力的方法,尤其适用于构建更小、更高效的模型。但其局限在于:蒸馏本身无法推动创新,也无法催生下一代推理模型——因为它始终依赖于一个已有的、更强的模型来生成监督微调(SFT)数据。
接下来一个值得关注的方向,是将 RL + SFT(策略3)与 推理时扩展(策略1)相结合。这很可能正是 OpenAI 在 o1 中采用的做法,只不过 o1 的基础模型可能弱于 DeepSeek-R1,这也解释了为何 DeepSeek-R1 在推理时既高效又表现出色。
关于 DeepSeek R1 的思考
谈谈我对 DeepSeek-R1 模型的看法。简而言之,我认为这是一项了不起的成就。作为一名算法工程师,我尤其欣赏其详尽的技术报告,其中披露的方法论对我极具启发和学习价值。
最令人着迷的发现之一,是推理能力竟能从纯强化学习中自发涌现。此外,DeepSeek 将模型以宽松的 MIT 开源许可证发布,其限制甚至比 Meta 的 Llama 系列模型还要少,这一点也令人印象深刻。
与 o1 相比如何?
DeepSeek-R1 是否优于 o1?我认为两者大致处于同一水平。但 DeepSeek-R1 的突出优势在于推理效率更高。这表明 DeepSeek 可能在训练阶段投入更多,而 OpenAI 则可能更依赖推理时扩展来提升 o1 的性能。
不过,由于 OpenAI 并未公开 o1 的细节,直接比较仍属“苹果与橘子”的对比。例如,我们尚不清楚:
- o1 是否也是混合专家模型(MoE)?
- o1 的实际规模有多大?
- o1 是否只是 GPT-4o 的轻微改进版,仅辅以少量 RL + SFT,主要依靠大量推理时扩展?
在缺乏这些关键信息的情况下,任何直接对比都只能是推测。
DeepSeek-R1 的训练成本
另一个热议话题是 DeepSeek-R1 的开发成本。有人提到约4300万元的训练费用,但这很可能是将 DeepSeek-V3(2024 年 12 月发布的基座模型)与 DeepSeek-R1 混淆了。
4300万元的估算基于假设 GPU 小时单价为14元,并参考了 DeepSeek-V3 最终训练轮次所需的 GPU 小时数——该数据最早在 2024 年 12 月被讨论过。
然而,DeepSeek 团队从未披露 R1 的确切 GPU 小时数或开发成本,因此所有相关成本估计都纯属猜测。
无论如何,DeepSeek-R1 无疑是开源权重推理模型领域的一个重要里程碑,其高效的推理表现使其成为 OpenAI o1 的一个有趣替代方案。
在有限预算下开发推理模型
即使以 DeepSeek-V3 这类开源基座模型为起点,要开发出 DeepSeek-R1 级别的推理模型,仍可能需要数十万至数百万美元的资金投入。这对预算有限的研究人员或工程师来说,无疑令人望而却步。
好消息是:蒸馏能走得很远。
幸运的是,模型蒸馏提供了一种更具成本效益的替代路径。DeepSeek 团队通过其 R1 蒸馏模型证明了这一点:尽管参数规模远小于 DeepSeek-R1,这些小型模型仍展现出令人惊讶的强推理能力。当然,即便如此,该方法也并非完全廉价——他们的蒸馏过程使用了 80 万条 SFT 样本,仍需大量算力支持。
有趣的是,在 DeepSeek-R1 发布前几天,我偶然看到一篇关于 Sky-T1 的文章:一个小型团队仅用 1.7 万条 SFT 样本就训练出了一个开源的 32B 模型,总成本仅为 450 美元——甚至低于大多数 AI 会议的注册费。
这一案例表明:尽管大规模训练依然昂贵,但小规模、有针对性的微调工作,仍能以极低成本取得令人印象深刻的结果。
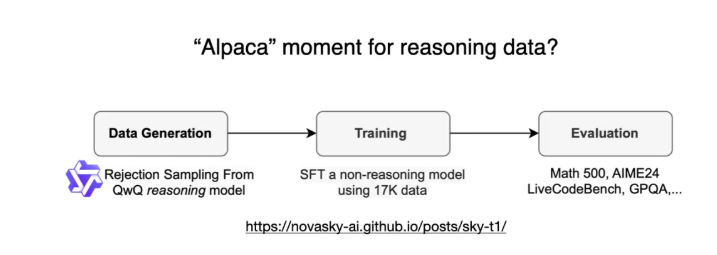
根据其基准测试,Sky-T1 的性能大致与 o1 相当,考虑到其极低的训练成本,这一表现令人印象深刻。
低成本下的纯强化学习:TinyZero
虽然 Sky-T1 聚焦于模型蒸馏,我也注意到“纯强化学习”(pure RL)领域一些有趣的工作。其中一个突出的例子是 TinyZero——一个仅含 30 亿参数(3B)的模型,它复现了 DeepSeek-R1-Zero 的方法(顺便一提:其训练成本不到 30 美元)。
令人惊讶的是,即使规模仅有 3B 参数,TinyZero 仍展现出一定的涌现式自验证能力(emergent self-verification abilities),这进一步支持了一个观点:即使在小型模型中,推理能力也能通过纯强化学习自然涌现。
TinyZero 的代码仓库提到,相关研究报告仍在撰写中。后续期待更多细节的公布。
上述两个项目表明,即使预算有限,依然可以开展富有成效的推理模型研究。尽管这两种方法都借鉴了 DeepSeek-R1 的思路——TinyZero 聚焦于纯强化学习(pure RL),而 Sky-T1 则专注于纯监督微调(pure SFT)——但更令人期待的是,这些思路未来还能如何进一步拓展和深化。
超越传统 SFT:旅程学习(Journey Learning)
去年我接触到一种特别有趣的方法,见于论文《O1 Replication Journey: A Strategic Progress Report – Part 1》。尽管标题提到“复现 o1”,但该论文实际上并未真正复现 o1,而是提出了一种改进蒸馏(即纯 SFT)过程的新思路。
论文的核心思想是用 “旅程学习”(journey learning)替代传统的 “捷径学习”(shortcut learning)。
- 捷径学习
- 而 旅程学习 则同时包含错误的解题路径及其修正过程,使模型能够从错误中学习。
这种方法在某种程度上与 TinyZero 在纯强化学习训练中观察到的自验证能力相关,但其目标是完全通过 SFT 来提升模型性能。通过向模型展示错误的推理路径以及对应的纠正方式,旅程学习有望增强模型的自我纠错能力,从而以这种方式构建出更可靠、更稳健的推理模型。
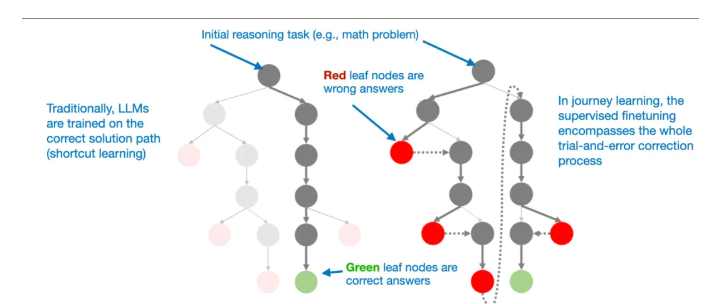
这可能是一个令人兴奋的未来研究方向,尤其适用于预算有限的推理模型开发场景——在这些场景中,基于强化学习(RL)的方法可能因计算成本过高而难以实施。
无论如何,目前在推理模型领域正涌现出大量有趣的工作,我相信在接下来的时间里,我们一定会看到更多令人振奋的成果!
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。