



什么是VLA大模型?VLA大模型如何应用于智能驾驶?
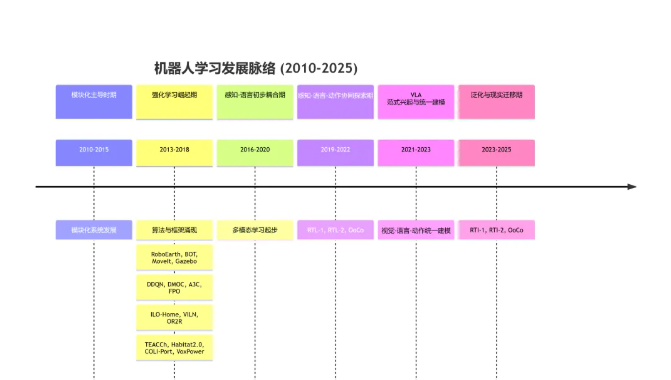
一、 VLA大模型历史发展
视觉–语言–动作(vision-language-action, VLA)模型在 2023 年 7月谷歌 DeepMind 发布 RT-2[1] 模型时首次被正式提出,引发了学术界对多模态感知与机器人动作一体化的广泛关注。随后,斯坦福大学等机构于 2024 年发布 OpenVLA[2] 开源框架,进一步促进了社区对VLA 模型研究的热情。
在VLA统一范式尚未兴起之前, 具身智能系统的发展主要依赖于模块化架构、策略学习方法以及多模态耦合机制的初步探索. 尽管这些方向在特定任务上取得一定成果, 但由于缺乏统一语义空间和跨模态协同机制, 普遍存在泛化能力不足、模型复用性低、适应性差等问题, 成为通用具身智能发展的制约因素. 如图所示, 前VLA时代的具身智能主要经历模块化范式、强化/模仿学习和早期感知–语言耦合等阶段,这些探索共同奠定了后续VLA提出的技术基础。
二、国内将VLA大模型上车的不同观点
2025年7月29日,理想i8发布,VLA同步亮相,i8成为第一款搭载VLA大模型的理想车型。另一边是,在之前召开的世界人工智能大会期间,博世智能驾控中国区总裁吴永桥表示,VLA短期难以落地,博世坚定投入一段式端到端。他认为,多模态大模型的特征对齐(视觉、语言、动作)很难实现;多模态的数据获取和训练也十分困难。最重要的是,VLA模型要部署在智驾芯片上,才能实现行车安全以及驾驶高度拟人化,但目前市面上几乎所有的三方智驾芯片都不是专为大模型的计算而设计的。“可能要在3~5 年之后,有了真正能跑大模型的芯片,才能支持 VLA 落地。”他说。
VLA 模型正备受推崇,有人称,2025 年是 VLA 元年,但也有人认为短期内真正的VLA技术难以落地。那么,从现在的技术储备来看,VLA让车学会“联想”的“野心”真的能实现吗?VLA技术大规模落地要到什么时候?
三、传统模型与VLA模型对比
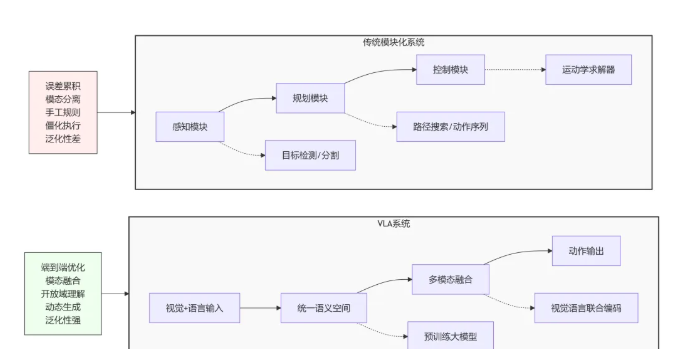
目前,端到端模型技术已经趋近成熟,很多车型都支持端到端大模型。但是,在一些复杂推理场景下,VLA大模型能力完胜端到端大模型。端到端模型是将传感器输入数据直接映射为转向、加速等车辆控制指令的单层架构,其核心优势在于简化流程、减少级联误差。例如,特斯拉于2023年推出的 FSD V12,就应用了一段式端到端架构,相较此前FSD V11的30 万行程序代码,V12 仅需约2000行代码,减少了对人工规则编程的依赖。但是,行业有观点认为,端到端模型存在“黑箱”,即其中的神经网络权重调整、特征提取以及决策制定过程均通过数据驱动的自主学习完成,整个信息处理链中不存在显式的逻辑规则或可分解的推理环节。因此,当遇到异常情况或罕见场景时,模型的决策可能会变得不可预测。通俗地说,也就是在一定程度上缺乏复杂场景的推理能力。
VLA能够更好地解决上述问题。VLA模型的主要优势在于模型一体化以及更强的泛化性,即应对复杂场景的能力。VLA是多模态大模型驱动的智能体架构,其核心突破在于引入思维链,通过语言模型实现对环境理解与决策推理的可解释性。例如,在潮汐车道场景中,VLA能通过文本指令和视觉信号综合判断车道可用性,并通过转向灯与其他车辆交互。同时,通过多模态深度融合、泛化能力跃升,可达到拟人化决策能力,通过模仿人类驾驶员的“观察-思考-行动”逻辑,实现更准确、自然的驾驶。在环岛通行等复杂场景中,VLA可基于地图信息、交通标志和实时车流生成多步规划,而传统端到端仅能输出单步控制指令。另外,VLA还能通过仿真环境和强化学习生成高价值数据,如通过世界模型仿真系统单日可进行智能驾驶测试 30 万公里,显著降低了对实车数据的依赖。
下图为传统模块化系统与VLA系统的架构对比图:
四、VLA模型目前的挑战
目前仍然存在亟待解决的问题:
- 数据规模:要增加到多大,才能呈现出“联想”能力(利用 Transformer 架构大模型的规模定律,在超过某个阈值后,可能得到举一反三、融会贯通与触类旁通的能力);
- 需要巨量的 AI 算力与数据的支撑,目前大部分企业是否有这样的资源;
- 仿真数据与实车测试的闭环优化:将多模态对齐误差控制在可接受范围;在世界模型构建方面,VLA 通过仿真系统生成虚拟场景,训练模型对物理规律(如车辆动力学)和社会规则(如让行优先级)进行理解。五、对VLA模型展望
VLA的大规模落地,本质是算法、算力、数据技术革命的交汇。短期(2025~2026年)具备VLA功能的车型将在高速公路、封闭园区等特定场景运行,典型应用包括自动泊车、高速领航等。中期(2027~2029年),随着算力达 2000TOPS 及以上新一代 AI 芯片量产,VLA 将覆盖城市道路全场景,平均无接管里程将显著提升,或突破100公里,接管率或降至0.01次/公里以下。长期(2030年后),将出现如光计算架构等专用AI芯片,并与脑机接口技术融合,或将使 VLA 实现类人驾驶的直觉决策能力,如准确预判行人突发行为的概率等。“多模态对齐成熟度、训练效率提升、芯片能效比革命等一些关键因素,都可能在未来3~5年迎来新的突破,为VLA大规模落地提供更好支持。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。