



为什么说每个模型都有独特的“性格”?
“ 每个模型都会有其独特的性格,我们需要理清不同模型的性格差异。”
最近在优化智能体长对话功能中,为了解决长对话存在的问题,采用了更换模型的方式进行对比测试;测试在长对话中,模型对整个系统的影响到底有多大。
然后就发现了一些很好玩的事情,也是不同模型之间的区别。
模型对比测试
在测试智能体长对话过程中,使用了所有优化方式,但最终还是没有达到预设的效果;因此,这时就怀疑是不是模型的问题,换一个更大更强的模型是不是会更好一点。
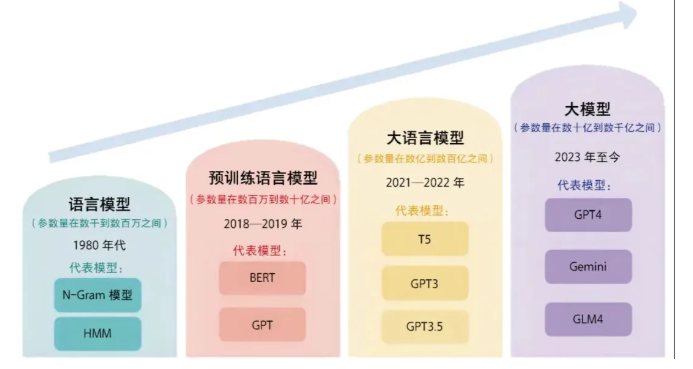
在现有的大模型体系中,大家有一个明显的共识,那就是模型参数越多,模型越大功能就越强,当然消耗的算力也更多。所以,现在的模型基本上都是多少多少B,这里B指的是十亿,所谓的14B就是140亿参数,32B就是320亿参数。
作者在测试中,先使用了14B的模型,30B的模型,80B的模型和最大235B的模型,从整体上来说除了14B之外,后面三个模型在对话场景中的差别并不是特别大。
只不过参数量越大,其行为模式越像人,但其思考的过程也越长,废话也越多;从测试的感受来看,越大的模型在交互上做得越好,当模型无法确认你的意图时,它会引导你做出更合适的输入;而这就是是小模型所无法比拟的。

但同样的,大模型也有大模型的问题,比如在使用235B的模型测试时发现,它会利用一部分参考数据,但也会根据自己的知识回答问题,而且从回复的内容来看,它自信心太强了,甚至有点过头。
而这在真实的业务场景中是不可取的,从这里也可以看出,模型并不是越大越好;从现有的模型设计来看,越大的模型越适合复杂的任务,但在简单的业务场景中,其表现可能并不一定会比小模型更好,甚至成本会更高,风险也更高。
其次,在大模型应用中模型作为一个可插拔组件,很多人都认为用小模型把流程和功能跑通,然后在生产环境直接切换大模型就可以了。
但经过今天的测试发现,每个模型由于训练数据和部署环境的不同,会导致不同的模型具备独特的风格;同样的提示词,同样的代码虽然在不同的模型上都能跑通;但效果上却可能天差地别。
所以,在真正的企业级环境中,我们需要针对不同的模型,进行适当的调整,特别是提示词和上下文;最好的方式就是,测试环境用什么模型,生产环境也用什么模型,这样才能尽可能的保证环境的切换对整个应用影响最小。
模型就像一个人,当它被训练完成之后,它就会具备其独特的风格,就类似于人的性格一样;除非对模型进行重新训练或微调,才能从根本上改变其“性格”。
而对待不同性格的人,需要使用不同的方式,同样对待模型也是如此;我们千万不能认为模型都是一样的,可以进行无缝切换。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。