



2026 主流 AI 模型深度对比:Claude、Gemini、豆包、DeepSeek 谁更适合工作?

我们每天都在用AI工作。但大多数人选AI的方式是"谁免费用谁"或者"谁火用谁"。
换个思路想想:如果你要招一个助理,你会怎么评估?你一定会看几个核心能力维度,而不是只看"这人要不要工资"。
我们就用这个方法,来评估当下最主流的几个AI模型。
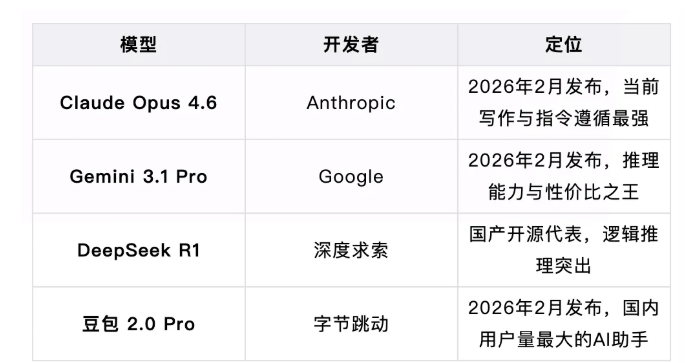
本文重点评估的模型
OpenAI的GPT-5系列能力确实很强,在部分基准测试中甚至排名第一。但问题是——最强的GPT-5 Pro模式需要每月200美元(约1450元人民币),是Claude和Gemini订阅价格的10倍。
普通的ChatGPT Plus(20美元/月)能用到的GPT-5.2,在写作和推理上并没有明显超越Claude或Gemini。所以对大多数知识工作者来说,GPT在工作产出的性价比不高。本文不做重点讨论。
我们从知识工作者和内容创作者最关心的五个维度来做评估:
维度一:写作质量——你的文字功底怎么样?
为什么这个维度排第一? 因为对知识工作者和内容创作者来说,写作产出是最核心的工作。做课程要写文案、做IP要写文章、做咨询要写方案。你的AI写作质量,直接决定了你的内容质量。
Claude Opus 4.6 ⭐⭐⭐⭐⭐
Claude在写作领域的地位,目前没有任何模型能撼动。
「晚点LatePost」做过一个14个模型的周报盲评测试:让AI扮演领导来鉴别哪份周报是AI写的。结果,Claude是唯一被判定为"像人写的"那份——因为它的结构不会过于工整,不会均匀堆砌"赋能""抓手""痛点"等管理黑话,会夹杂真实的口语化表达。
Claude写东西更像一个"有主见的同事在表达观点",而不是"一个工具在执行指令"。它会主动指出你论证中的薄弱环节、提供你没想到的视角。在长篇写作的一致性、修改配合度、论述深度上,多个独立评测机构都把Claude排在第一。
Gemini 3.1 Pro ⭐⭐⭐⭐
Gemini的写作整体扎实,结构清晰、信息准确。但风格偏"中正稳妥",用DataCamp评测的话来说,产出质量高但缺少个人辨识度。如果你的品牌调性本身就是平实、实用的,这反而是个优点,我个人反而更喜欢Gemini 3 Pro。
DeepSeek ⭐⭐⭐☆
DeepSeek的写作优势在学术和分析类内容上——逻辑严密、条理分明,非常适合写研究报告、数据分析、行业深度拆解这类理性内容。但在文学性表达和个人风格上较弱,整体被评价为"偏保守",需要额外的风格调教。如果你主要做学术类、分析类内容,DeepSeek是一个不错的免费选择。
豆包 2.0 Pro ⭐⭐⭐
豆包2.0在写作上相比1.x有明显进步,尤其是指令遵循和格式输出更稳定了。豆包App内置了丰富的写作模板(公众号文章、小红书文案等),让写作的启动成本很低。
但也正因为用户基数大、模板使用率高,豆包产出的内容同质化是一个客观存在的问题。如果你是做个人IP的,需要注意调整和二次加工,避免读者一眼识别出"AI味"。
维度二:深度推理——遇到复杂问题你能想多深?
为什么这个维度重要? 做课程设计、写深度文章、拆解商业模式、做用户分析——这些知识工作者的高价值任务,本质上都是复杂推理。一个AI能不能帮你真正"想通"一个问题,比它能不能"回答"一个问题重要得多。
Gemini 3.1 Pro ⭐⭐⭐⭐⭐
深度推理是Gemini 3.1 Pro最亮眼的能力。
在ARC-AGI-2测试(评估AI解决全新未见过的逻辑问题的能力)上,Gemini 3.1 Pro拿到了77.1%,相比上一代Gemini 3 Pro的31.1%直接翻倍,大幅领先Claude Opus 4.6的68.8%和GPT-5.2的52.9%。
ARC-AGI-2之所以重要,是因为它不测"背答案"的能力,而是测"面对全新问题能不能想出解法"的能力。
对知识工作者来说,你遇到的大多数问题都没有标准答案——需要的正是这种推理能力。
Claude Opus 4.6 ⭐⭐⭐⭐☆
Claude的推理跑分不是最高的,但有一个独特优势:当它可以使用工具(搜索、计算等)来辅助推理时,它反而超过了Gemini。
在HLE(人类最后的考试)中:
- 无工具时:Gemini 44.4% > Claude 40.0%
- 有工具时:Claude 53.1% > Gemini 51.4%
在真实工作场景中,我们不会让AI"闭卷考试"——我们会给它资料参考、让它联网搜索。在这种更接近实际工作的条件下,Claude的推理表现反而更强。
豆包 2.0 Pro ⭐⭐⭐⭐
豆包2.0的推理能力是2月这次升级的重头戏。官方数据显示,豆包2.0 Pro在IMO(国际数学奥林匹克)、CMO数学竞赛和ICPC编程竞赛评测中拿到了金牌成绩,在Putnam数学基准测试上超越了Gemini 3 Pro。在HLE-Text测试中更是拿到了54.2的高分。
科学领域知识测试成绩也与Gemini 3 Pro和GPT-5.2相当。这是国产模型在推理能力上的一次重要突破,值得肯定。
不过需要注意的是,这些主要是官方自报数据,而且豆包2.02月才发布,还需要更多独立第三方评测来验证实际表现。官方自己也说:"模型已经能解竞赛题,但放在真实世界里仍然很难端到端完成实际任务。"
DeepSeek R1 ⭐⭐⭐⭐
DeepSeek R1的推理能力是它的王牌,尤其在数学和逻辑推理上非常突出。但是一年下来没什么迭代,没有太多亮眼的地方。
维度三:指令遵循——交给你的活儿能按要求完成吗?
为什么这个维度重要? 这是区分"能用"和"好用"的关键。知识工作者给AI的指令往往是复杂的——不是"帮我翻译这句话",而是:
"把这篇5000字的稿子改成一个20分钟的演讲稿,开头用反直觉数据抓注意力,穿插3个案例,口语化但保持专业感,结尾有行动号召,不要出现'赋能''闭环'这类词,全文控制在3000字以内。"
能不能同时满足这么多约束条件,是AI能力的真正分水岭。
Claude Opus 4.6 ⭐⭐⭐⭐⭐
这是Claude最碾压其他模型的维度。
GDPval-AA是一个测试真实办公场景中专家级任务能力的评测(包括数据分析、报告撰写、方案设计等),这个评测的结果非常说明问题:
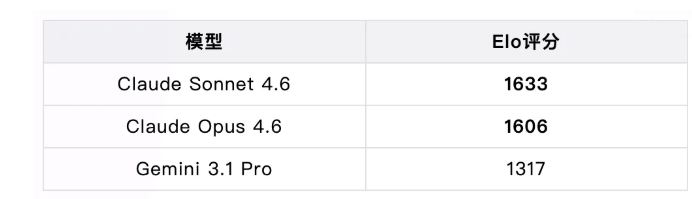
Claude领先近300个Elo点。 这在评分体系中是一个巨大的差距——相当于一个职业棋手和一个业余高手的区别。
具体表现为:你给Claude一个有七八个约束条件的复杂指令,它能同时记住并满足所有条件。你让它反复修改同一篇文章,它能保持全局一致性而不会改着改着前后矛盾。这对于内容创作者的日常工作(反复迭代打磨一篇重要文章、设计一套课程体系、撰写一份完整方案)来说,是最直接的效率提升。
Gemini 3.1 Pro ⭐⭐⭐☆
Gemini在执行指令时偏向"按部就班完成任务",对标准化的结构性任务完成度不错。但在需要大量主观判断和风格把控的任务中,缺少Claude那种主动思考和优化建议的能力。
值得一提的是,Gemini在Agent类任务(多步骤自主执行)方面有独特优势,MCP Atlas评测中Gemini得分69.2%,Claude为59.5%。如果你让AI自主完成一个多步骤工作流(比如"先搜索资料、再分析、再撰写报告"),Gemini的自主执行能力更强。
豆包 2.0 Pro ⭐⭐⭐☆
豆包2.0在指令遵循上有明显进步。官方数据显示在指令遵循、工具调用和Search Agent等评测中达到顶级水平,格式输出更稳定。企业级Agent能力也是这次升级的重点,支持灵活的上下文管理和多轮指令遵循。
但在真实使用场景中,长对话的上下文保持能力仍是一个需要关注的点——这直接影响你反复打磨一篇重要文章的体验。
DeepSeek ⭐⭐⭐
DeepSeek在执行结构化指令时表现不错,但在需要多轮迭代修改的场景中容易丢失上下文。加上服务器稳定性问题,复杂任务的执行体验经常被打断。
维度四:创意与风格化能力——能帮我写出"我自己的风格"吗?
为什么这个维度重要? 对做个人IP的内容创作者来说,最怕的不是AI写不出来,而是AI写出来的东西"谁都能写"。如果你的文章读起来和别人用AI生成的没区别,那你的个人品牌就没有辨识度。真正有价值的AI助手,是能帮你放大你自己的风格,而不是把你的风格抹平成千篇一律的"AI体"。
Claude Opus 4.6 ⭐⭐⭐⭐⭐
这是Claude最让用户喜欢的地方。
Claude不只是"完成任务",它能理解你想要的调性。你给它看几篇你之前写的文章,它能学会你的节奏和表达习惯。它会给出你意想不到的角度和比喻,但又不会偏离你的核心论点。在需要创意输出的场景(标题构思、文案打磨、开头设计)中,Claude的产出常常能直接触发"就是这个感觉"的瞬间。
多个评测指出,Claude的产出风格更接近"一个有观点的作者",而不是"一个信息整理机器"。这种差异在短文案中可能不明显,但在长篇深度内容中,差距非常大。
Gemini 3.1 Pro ⭐⭐⭐☆
Gemini的创意和设计能力在"AI编程"(Vibe Coding)中得到了广泛认可——你描述一种感觉,它能把感觉转化为产品。有用户让它"做一个让人不会感到乏味的404页面",Gemini理解了"乏味"背后的体验需求,直接给出了有趣味性的完整方案。
在文字创作领域,Gemini的产出偏向"平实"。它不太会主动挑战你的思路或给出让你眼前一亮的表达。如果你给它足够详细的风格指令,它能模仿。
DeepSeek ⭐⭐⭐
DeepSeek的风格偏向严谨、理性,在学术写作和分析报告中这是优势。但在需要个性化表达、幽默感、文学性的创作场景中,它的产出明显"端着"。
豆包 2.0 Pro ⭐⭐⭐
豆包2.0在多模态理解上有显著进步——它能看懂恶搞图片背后的"梗",不会机械地介绍内容而是理解语境。这说明豆包的"理解力"在提升。
但在文字创意输出上,豆包目前的核心优势还是"模板丰富、启动快",而不是"风格独特、有辨识度"。对于需要批量产出标准化内容(比如产品描述、活动文案)的场景,豆包效率很高。但如果你要打造有辨识度的个人IP内容,还是需要更高阶的模型来辅助。
维度五:靠谱程度——说的话能信几分?
为什么这个维度重要? 如果你是老师,课堂上引用AI给的错误数据,会被人质疑你的专业性。如果你做知识付费,文章有事实错误,用户会质疑你所有内容的可信度。AI的"幻觉"(看似合理但实际错误的信息)是知识工作者的最大风险。
Claude Opus 4.6 ⭐⭐⭐⭐⭐
在香港大学对37个主流模型的幻觉控制能力深度测评中,Claude 4 Opus系列处于国际一线水平。
但Claude真正的优势不只是"少犯错"——而是它**"知道自己不知道什么"**。当它对某个信息不确定时,会主动标注不确定性,而不是自信地编造一个听起来合理的答案。对知识工作者来说,这种"诚实的不确定"比"自信的错误"有价值得多。你可以放心地基于Claude的回答去做进一步判断,因为它不会给你一个看似权威实则编造的结论。
Gemini 3.1 Pro ⭐⭐⭐⭐
Gemini 3.1 Pro在事实准确性上有显著进步。Gemini 3 Pro在SimpleQA(事实准确性)上的突破使得模型幻觉大幅降低。3.1版本在此基础上进一步提升了推理准确率。
但也有用户发现Gemini在部分场景中会"硬撑"——明明不确定,却不主动联网验证,而是用自己的旧知识给出一个可能已过时的答案。使用时建议主动要求它搜索验证关键信息。
豆包 2.0 Pro ⭐⭐⭐☆
豆包2.0在知识覆盖上做了大量扩展,科学领域知识测试成绩与Gemini 3 Pro和GPT-5.2相当。在HealthBench专业医疗测评中排名靠前,SuperGPQA研究生级问答测试中也有不错表现。
但在港大的幻觉评测中,即便是国产最佳表现者,与国际前沿模型之间仍存在差距。豆包2.0正在持续优化深度思考功能来降低幻觉率,这个方向是对的,但还在追赶过程中。对于要用在正式场景(课堂、知识付费、客户方案)中的关键信息,建议做二次核实。
DeepSeek ⭐⭐⭐
清华大学新媒体研究中心的测试显示,DeepSeek在幻觉率上表现中等。R1通过长思维链推理降低了部分幻觉,但在非推理类的日常问答中仍需警惕。而且DeepSeek会"变风格"——有用户反馈DeepSeek回答突然变得"冷淡",官方回应说不是故意的,可能是多方面原因叠加。
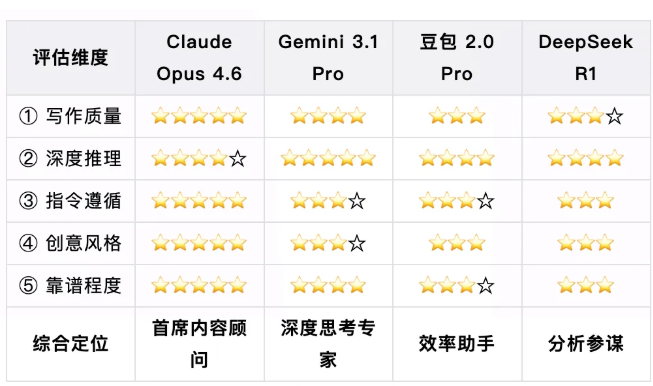
总分对比表
那我到底该怎么用?
一句话总结:核心内容用Claude,深度思考用Gemini,日常辅助用国产。
更具体地说:
做课程设计、深度文章、个人IP内容 → 首选Claude Opus 4.6或Claude Sonnet 4.6(优先推荐Sonnet,性价比最高)。写作质量、指令遵循和风格化能力是目前所有模型中最强的,能让你的内容产出效率翻倍,而且产出质量明显高于其他模型。
需要深度推理和复杂分析 → 首选Gemini 3.1 Pro或Gemini 3 Pro。无论是拆解商业模式、做竞品分析还是解决技术难题,Gemini的深度思考能力是当前最强的。
学术报告和数据分析 → DeepSeek R1是一个不错的免费选择,逻辑推理能力确实强,只是别让它做太多创意写作。
快速问答和日常小任务 → 豆包2.0免费、响应快、中文体验好。但核心的内容产出不建议完全依赖它。
费用对比
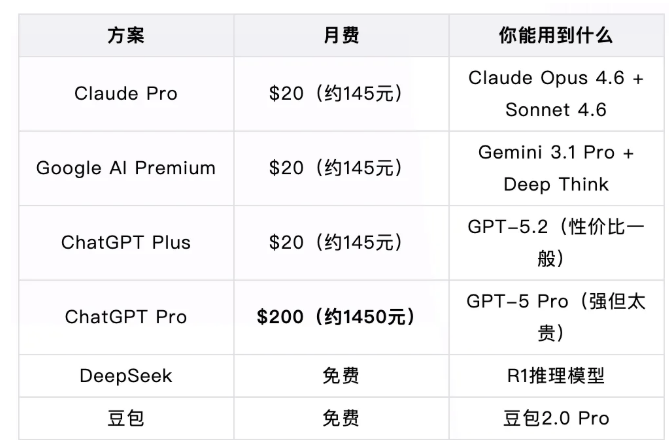
如果你的收入来源依赖于内容质量,每月一两百元的AI工具投入换来的是内容效率和质量的显著提升——这是投资回报率极高的决策。
但你其实不需要分别订阅多个平台。
推荐方案:新个体AI
我们的新个体AI平台(xingeti.com)已经集成了上面提到的所有主力模型:
- Claude Opus 4.6 / Claude Sonnet 4.6 — 写作与内容创作的首选
- Gemini 3 Pro — 深度推理与复杂分析
- GPT-5系列 — 需要时随时调用
- 国内主流模型 — 豆包、DeepSeek等一站可用
一个平台,所有主力模型随时切换。不用分别注册多个账号、不用处理海外支付,直接上手用最好的工具做最重要的事。
大多数内容创作者和知识工作者目前不需要编程能力,但如果你打算进一步用AI来构建属于自己的产品,可以在新个体AI社群中了解更多。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。