



robots.txt 正确写法是什么?爬虫规则如何设置?

在现代 Web 开发中,技术 SEO 是确保网站能够被搜索引擎正确索引和排名的关键。
不做 SEO:
- 网站处于隐形状态:除非用户直接输入网站,否则没人能通过搜索找到你的网站
- 收录混乱:搜索引擎不收录你的页面,或是收录的无效页面
- 仅能靠付费推广:想要流量只能付费做广告或者社交媒体推广
- 裸链接:用户分享网址时只能是蓝色 URL 链接,可能被识别为垃圾信息
- 品牌信任度:用户难以搜索到网站,降低网站的可信度
做了 SEO:
- 主动被发现:搜索关键词时你的网站会得到推荐,增加流量
- 收录全面:搜索引擎知道网站有哪些页面,网站内容更新后会很快被搜索到
- 免费且持久:搜索引擎会长期维护你的网站,排名稳定后,会有源源不断的流量
- 优雅的展示封面:分享会展示精美的网站封面,提升用户点击率
- 技术红利:做了 SEO,会优化内容结构,变相提升网站的技术
- 背书效应:用户潜意识里认为排在前面的网站更权威、更正规SEO 这么有用,但一般人的实现却是:
- 加个 <title> 标签
- 加几个 <meta> 关键词
真正有用、高效的 SEO 要怎么做呢?
SEO 核心概念
先来了解一下 SEO 的一些核心概念。
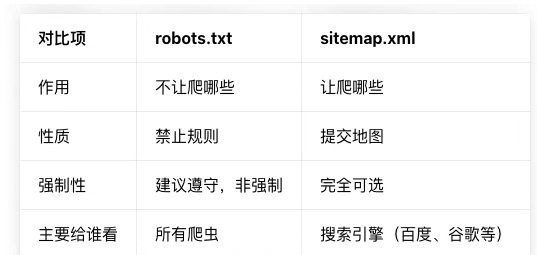
sitemap.xml 是什么?
作用:给搜索引擎指路
功能:
列出你希望被收录的所有页面
告诉页面更新时间、优先级
- 示例
<url> <loc>https://xxx.com/page1</loc> <lastmod>2026-02-12</lastmod> <priority>0.8</priority></url>robots.txt 是什么?
- 作用:给搜索引擎定规矩
- 功能:
- 禁止某些爬虫
- 禁止爬某些目录 / 页面
- 告诉爬虫去哪里找 sitemap
- 示例
User-agent: *Disallow: /admin/Disallow: /private.htmlAllow: /Sitemap: https://xxx.com/sitemap.xml
Schema.org 是什么?
- 作用
给 Google、百度、必应 等搜索引擎看的,告诉它们:
- 这是什么内容(文章?产品?视频?人?)
- 标题是什么
- 发布时间
- 作者
- 评分
- 目录结构
- 功能
- 示例
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "Article", "headline": "文章标题", "author": { "@type": "Person", "name": "作者" } }</script>OG Image 是什么?
当你把网页分享到微信、QQ、抖音、小红书、Discord、Facebook时,显示的那张封面图,就是 OG Image。
- 作用
- 控制分享出去长什么样
- 没有它,分享可能没封面图、显示效果差
- 功能
- 优化分享效果
- 提升社交媒体分享的点击率和用户互动
- 示例
<meta property="og:title" content="标题" /><meta property="og:description" content="描述" /><meta property="og:image" content="https://xxx.com/cover.jpg" />

Nuxt SEO
Nuxt SEO 是一套 SEO 元模块,其中包含多个模块:

- @nuxtjs/sitemap: 智能生成站点地图
- @nuxtjs/robots: 管理爬虫访问规则
- nuxt-og-image: 动态生成社交分享图片
- nuxt-schema-org: 注入结构化数据 (JSON-LD)
- nuxt-seo-utils: 提供通用的 SEO 工具函数
核心优势:
- 自动化:自动生成 robots.txt、sitemap.xml 和 og:image。
- 最佳实践:默认遵循 Google 等搜索引擎的推荐标准。
- 开发体验:与 Nuxt DevTools 深度集成,提供实时的 SEO 调试能力。
快速开始
了解完以上概念后,接下来开始提升网站的 SEO 效果。
安装
pnpm i @nuxtjs/seo配置
在 nuxt.config.ts 中进行配置。最重要的是设置 site.url,它是生成 Sitemap 和 Canonical URL 的基础。
export default defineNuxtConfig({ modules: ["@nuxtjs/seo"], site: { url: "https://example.com", // 网站域名 name: "我的 Nuxt 应用", description: "一个高性能的 Nuxt 网站", defaultLocale: "zh-CN", // 设置默认语言 },})开发调试
安装了 @nuxtjs/seo 后,启动项目打开 Nuxt DevTools,你会发现一个新的 SEO 选项卡:
- 实时检查:查看当前页面的 Meta 标签、OG 图片预览和 Schema 数据。
- 缺失提示:如果页面缺少关键的 SEO 信息(如 Title 或 Description),DevTools 会给出警告。
进阶配置
虽然 @nuxtjs/seo 已经提供了开箱即用的配置,但在实际生产环境中,我们往往需要更精细的控制。
@nuxtjs/sitemap
sitemap.xml 是搜索引擎发现你网站页面的地图。@nuxtjs/sitemap 模块会自动扫描你的静态路由,但对于动态内容(如博客文章、商品详情),我们需要手动告知它。
常用配置
// nuxt.config.tsexport default defineNuxtConfig({ sitemap: { // 1. 动态路由数据源:支持 API 端点 sources: ["/api/__sitemap__/urls"], // 2. 排除不需要被索引的页面 exclude: ["/user/**", "/admin/**", "/checkout"], // 3. 开启分块 (Chunking):适用于大型网站 (> 50k URL) sitemaps: true, },})对于动态路由,你可以创建一个 Server API (例如 server/api/__sitemap__/urls.ts) 来返回所有的文章链接。
如何验证配置是否生效?
本地启动项目,访问:http://localhost:3000/sitemap.xml;线上环境访问:https://yoursite.com/sitemap.xml,当看到 xml 内容既配置成功。
@nuxtjs/robots
robots.txt 定义了爬虫可以访问哪些区域。@nuxtjs/robots 的一大优势是它能根据环境自动切换策略:开发环境默认禁止所有爬虫,生产环境默认允许。
// nuxt.config.tsexport default defineNuxtConfig({ robots: { // 1. 全局爬虫规则(User-agent: * 对应 allRobots) allRobots: { // 禁止爬取的目录/页面(常用) Disallow: [ "/admin/", // 后台管理页 "/api/", // 接口目录 "/_nuxt/", // Nuxt 打包后的静态资源(可选,一般无需禁止) "/private/", // 私有页面 "/*.pdf$", // 禁止爬取所有 PDF 文件(正则写法) ], // 允许爬取的内容(覆盖 Disallow,可选) Allow: [ "/api/public/", // 允许爬取公开接口 ], // 爬虫抓取频率(可选,只是建议,非强制) CrawlDelay: 2, // 每次请求间隔 2 秒,减轻服务器压力 }, // 添加自定义规则 groups: [ { userAgent: ["Baiduspider"], // 针对百度爬虫的特殊规则 disallow: ["/api/"], // 禁止访问 allow: ["/api/public-data"], // 允许访问 }, { userAgent: "*", disallow: ["/secret", "/admin"], allow: "/", }, ], },})如何验证配置是否生效?
本地启动项目,访问:http://localhost:3000/robots.txt;线上环境访问:https://yoursite.com/robots.txt,会看到以下内容:
User-agent: *Disallow: /admin/Disallow: /api/Disallow: /private/Allow: /Crawl-delay: 2Sitemap: https://你的域名.com/sitemap.xmlUser-agent: BaiduspiderDisallow: /archive/nuxt-og-image
全局配置
// nuxt.config.tsexport default defineNuxtConfig({ modules: ["@nuxtjs/seo"], // Nuxt SEO 模块核心配置 seo: { // 基础站点信息(会自动复用为 OG 基础信息) site: { // ... }, // OG 标签全局配置(重点:ogImage) og: { // 全局默认 OG 类型 type: "website", // 全局默认 OG Image 配置(核心) image: { // 图片路径:推荐用绝对路径,或相对路径(模块会自动拼接 site.url) src: "/og-default.jpg", // 等价于 https://你的域名.com/og-default.jpg width: 1200, // 最优尺寸 height: 630, type: "image/jpeg", // 图片格式 alt: "网站默认分享封面", // 图片描述(可选,提升可访问性) }, // 全局默认语言 locale: "zh_CN", }, // 兼容 Twitter 卡片(可选,自动复用 ogImage) twitter: { card: "summary_large_image", // 大图卡片样式 }, },})单页面配置
单页面配置的内容会覆盖全局配置。
在具体页面(如 pages/article/[id].vue)中,用 useOgImage 或 useSeoMeta 自定义该页面的 OG Image:
<template> <div>详情页</div></template><script setup lang="ts"> // 1. 假设从接口获取文章数据 const article = await fetchArticleData() // 你的业务逻辑 const articleCover = article.coverImage || "/og-article-default.jpg" // 2. 方式1:单独修改 OG Image(推荐,更精准) useOgImage({ src: articleCover, // 自定义封面图路径 width: 1200, height: 630, alt: article.title, // 用文章标题作为图片描述 }) // 3. 方式2:批量修改 OG 信息(含 Image) useSeoMeta({ ogTitle: article.title, // 文章标题 ogDescription: article.summary, // 文章摘要 ogImage: [ { src: articleCover, width: 1200, height: 630, }, ], twitterImage: articleCover, // 兼容 Twitter })</script>动态路由批量配置
动态页面的配置可以结合sitemap来设置:
// nuxt.config.tsexport default defineNuxtConfig({ modules: ["@nuxtjs/seo"], sitemap: { // 动态生成路由 + 对应 OG Image routes: async () => { const articles = await fetchAllArticles() // 获取所有文章 return articles.map((article) => ({ url: `/article/${article.id}`, // 给每个路由绑定 OG Image seo: { ogImage: { src: article.coverImage, width: 1200, height: 630, }, }, })) }, },})如何验证配置是否生效?
启动项目,访问页面右键「页面源代码」,能看到 <meta property="og:image" content="你的图片URL"> 即配置成功。
SEO 进阶技巧与最佳实践
1. 喂饱搜索引擎
搜索引擎喜欢结构化数据。通过 Schema.org 标记,你可以让 Google 更精准地理解你的内容。
Nuxt SEO 提供了 useSchemaOrg 组合式函数,让你可以像写 Vue 组件一样编写 Schema:
<script setup lang="ts"> useSchemaOrg([ defineArticle({ image: '/images/cover.jpg', datePublished: '2026-02-18', author: { name: 'Trae', }, }) ])</script>2. 社交分享优化
当用户将你的链接分享到 Twitter 或微信时,一张精美的预览图能显著提高点击率。
- Open Graph 标签:自动生成 og:title, og:description 等标签。
- OG Image 生成:nuxt-og-image 模块可以根据你的页面内容(标题、摘要)动态生成 SVG 或 PNG 图片。这意味着你不需要为每篇文章手动通过 Photoshop 制作封面,代码即设计!
3. 链接与 URL 规范化
重复内容是 SEO 的大忌。Nuxt SEO 能帮你处理这些细节:
- Trailing Slashes:统一 URL 结尾是否带斜杠(例如 /about vs /about/),避免被视为两个页面。
- Canonical URLs:自动添加规范链接,告诉搜索引擎哪个是"正版"页面,防止参数(如 ?utm_source=...)导致权重分散。
多搜索引擎适配策略
不同的搜索引擎有不同的脾气,针对国内外的搜索巨头,可以采取差异化的策略。

Google 优化
Google 的爬虫能力最强,能够很好地执行 JavaScript。
- Core Web Vitals:重点关注 LCP (最大内容绘制)、CLS (累积布局偏移) 和 INP (交互到下一次绘制)。Nuxt 默认的性能优化通常能满足要求。
- Google Search Console:在 GSC 中主动提交你的 sitemap.xml,并定期查看"覆盖率"报告,修复 404 和 500 错误。
- 富媒体搜索结果:利用上文提到的 Schema 标记,争取在搜索结果中展示星级评分、问答等富媒体信息。
百度优化
百度爬虫对现代 JavaScript 的执行能力相对较弱,且对页面加载速度极其敏感。
- 确保 SSR 输出:这是最关键的一点。确保你的 Nuxt 应用以 SSR 模式运行,并且 HTML 源码中直接包含核心内容。
- 主动推送:百度非常依赖主动提交。看在网站上线后,通过 API 立即将链接推送到百度站长平台。
- URL 结构:百度更喜欢扁平、简单的 URL 结构,避免过深的层级和复杂的动态参数。
- 移动端适配:百度对移动端友好的站点有明显的加权,做好响应式适配移动端是一个不错的选择。
必应优化
Bing 在搜索端的占比越来越高,且是 ChatGPT 搜索的数据源之一。
- IndexNow 协议:Bing 大力推广 IndexNow 协议,允许网站在一个 URL 发生变化时立即通知搜索引擎。这比传统的 Sitemap 被动抓取要快得多。
- Bing Webmaster Tools:功能与 GSC 类似,建议注册并提交 Sitemap。
总结
SEO 是一个长期积累的过程,但 Nuxt SEO 模块帮我们扫清了技术障碍。通过合理的配置和使用,并针对 Google、百度等不同平台进行针对性优化,可以确保你的 Nuxt 应用在起跑线上就领先一步。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。