



AI是怎么读懂"文字的?Embedding让机器理解语义的奥秘
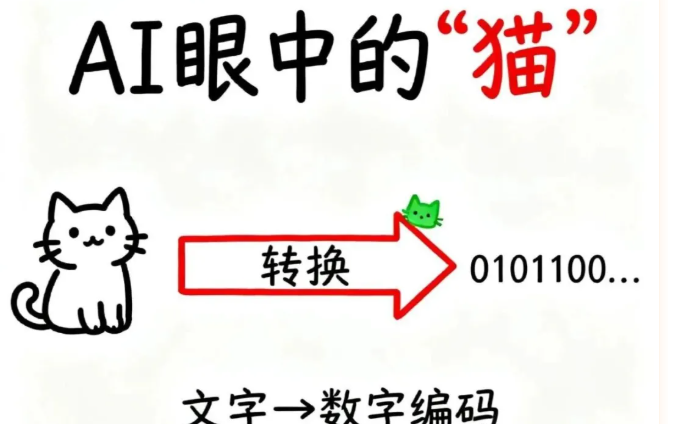
当AI看到"猫",它眼中是什么?
你有没有想过,当我们对着AI说"猫"这个字时,它的"大脑"里会浮现出什么?
我们人类看到"猫",脑海里立刻会出现一只毛茸茸、会喵喵叫的小动物,甚至能想象它软乎乎的触感和撒娇的模样。但对于大模型来说,猫不过是几个字符——一串冰冷的数字编码。
这听起来很机械,但正是这些看似冰冷的数字,让AI能够"理解"人类的语言,甚至做到比我们想象中更聪明的事情。今天,我们就来揭开这个秘密:AI究竟是如何从"看见文字"进化到"读懂语义"的?
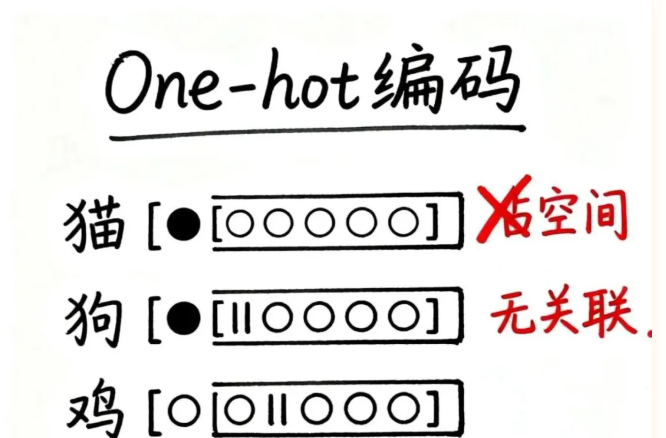
最初的尝试:One-hot编码的"开关游戏"
在计算机科学发展的早期,科学家们想了一个最直观的办法来让机器识别文字,叫做One-hot编码。
这个方法的逻辑非常简单:给每个词分配一个独一无二的位置,就像一排开关,只有对应的那一个位置是"1"(开),其他所有位置都是"0"(关)。比如:
- 猫:[1, 0, 0, 0, 0, …]
- 狗:[0, 1, 0, 0, 0, …]
- 鸡:[0, 0, 1, 0, 0, …]
听起来简单易懂,对吧?但这种方法有两个致命问题:
第一个问题是空间浪费严重。想象一下,如果你的词库里有10万个词,那每个词都要用一个长达10万位的编码来表示,其中只有1个位置是"1",其他99999个位置都是"0"。这就像为了找一个人,给全国每个城市都建一个标记点,实在太浪费了。
第二个问题更要命——完全看不出词语之间的关系。猫和狗都是宠物,鸡和鸭都是家禽,人类一眼就能看出它们的相似性。但在One-hot编码的眼里,它们只是毫无关联的编号,就像身份证号一样,彼此之间没有任何意义上的联系.
词袋模型:从"统计"中寻找线索
既然One-hot编码行不通,科学家们又想了个新办法:既然词语本身的编码看不出关系,那能不能通过统计词在文章中出现的次数来猜测内容讲了什么?
这就是词袋模型(Bag of Words)。它的思路是:当你看到一段文字里频繁出现"人工智能"“算法”"深度学习"这些词,你大概率能判断它和AI有关。通过这种方式,计算机可以做一些基础的文本分类、聚类,甚至是主题识别。
但词袋模型也有明显的局限:
- 对词的顺序不敏感。"小明打了小红"和"小红打了小明"在词袋模型眼里是一样的,因为它只看词的出现频率,不管谁先谁后。
- 同词不同意的情况无能为力。比如"我去银行取钱"和"我坐在河边的银行上",虽然都有"银行"这个词,但意思完全不同,词袋模型却分辨不出来。
显然,我们还需要更聪明的方法。
Embedding:让词语"住进"语义空间
科学家们开始思考:有没有办法通过词和词之间的上下文关系,让机器真正理解词语之间的语义关联呢?
Embedding模型应运而生,它带来了一场真正的革命。
和One-hot编码不同,Embedding模型不再为每个词分配一整串独立编号,而是把词语映射到一个高维的向量空间中。你可以把这个向量空间想象成一张巨大的地图,每个词对应地图上的一个坐标点。
这些点可不是随便乱放的,而是模型通过阅读海量文本学习得到的。比如:
- "猫"和"狗"经常出现在相似的语境中(“养猫”“养狗”“宠物猫”“宠物狗”),所以它们在这张地图上的位置会靠得很近。
- 而"猫"和"冰箱"几乎没什么关联,所以它们的坐标自然就离得很远。
更神奇的是,这种空间关系还能捕捉到更复杂的语义联系。比如,如果你计算"国王"减去"男人"再加上"女人",得到的坐标点会非常接近"女王"!
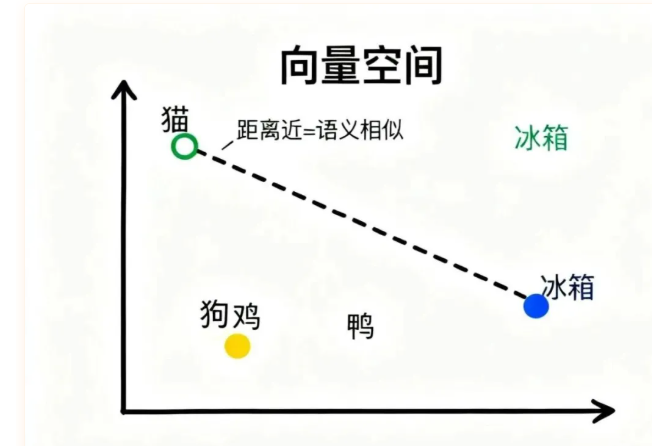
这种设计不仅大大节省了空间(每个词只需要几百个数字,而不是几万个),更重要的是,点和点之间的距离能够反映出词语之间的语义关系。
这让大模型不只是"看见文字",而是能够"读懂文字背后的深层含义"。这种理解力使得大模型在搜索、推荐、问答等任务中越来越聪明。
可以说,Embedding就是模型中的模型——它是让AI真正"懂人话"的核心技术。
写在最后:让机器真正"懂你"的未来
从最初简单粗暴的One-hot编码,到能够捕捉语义关系的Embedding模型,AI理解人类语言的能力正在经历质的飞跃。
而这背后,是无数科研人员的探索与创新。就像千问团队一样,他们不断思考"人民需要什么",然后就开源什么,让更多人能够享受到AI技术的红利。
下一次,当你对着AI说"猫"的时候,不妨想一想:在那些数字编码和向量空间的背后,是多少智慧的结晶,让机器真正开始"懂你"。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。