



LLM大模型是怎么“理解”问题的?
你有没有想过,你跟AI聊天,它秒懂你的梗,甚至比你男/女朋友还懂你,这到底是啥黑魔法?
它没上过学,没考过四六级,怎么就能一本正经地跟你讨论《三体》里的黑暗森林法则,还能帮你写代码、做PPT?
其实它一个字都不“认识”。
它既不知道啥是“宇宙”,也不明白啥是“烧烤”。那它是怎么做到“理解”并对答如流的?
这事儿不赖玄学,赖科学。咱们今天就把它扒个底朝天。
01
核心比喻
想象一下,LLM的“理解”过程,就像一个在宇宙中心摆摊、烤了亿万年串儿的“烧烤摊神级师傅”。
这位师傅没上过新东方烹饪学校,不懂什么分子料理理论,但他有个绝活:他烤过全宇宙的每一种食材,见过它们的所有排列组合。
我们可以这样拆解这个比喻:
- LLM (大语言模型) → 这位宇宙烧烤摊师傅。
- 词/Token (语言的基本单位) → 烧烤的食材(比如“羊肉”、“韭菜”、“奥尔良鸡翅”)。
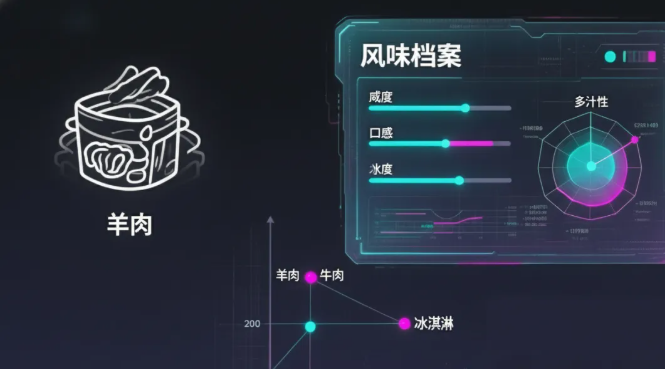
- 词向量 (Word Vector) → 食材的“风味档案”。这不是个简单的标签,而是一份超详细的数字化报告,记录了食材的咸度、甜度、口感等上千个维度。在这份档案里,“羊肉”和“牛肉”的坐标离得很近,但跟“冰淇淋”就隔着十万八千里。
- 上下文 (你输入的那句话) → 顾客下的订单(一根待烤的串儿)。比如订单是“羊肉、辣椒面、孜然……”。
- 自注意力机制 (Self-Attention) → 师傅的“火眼金睛”。他看一眼这串儿上的“羊肉”,眼神(注意力)会立刻自动锁定到“孜然”和“辣椒面”上,因为他亿万年的经验知道这几个是“黄金搭档”,同时会自动忽略旁边别人点的“蜂蜜”。
- 预训练 (Pre-training) → 师傅的“学徒生涯”。他的训练极其枯燥且暴力:只干一件事——预测下一个该放啥食材。给他一根只烤了“羊肉、辣椒面、孜然”的串,他必须猜出下一个大概率是“盐”。猜错了,宇宙法则就会电他一下。亿万次的“猜错-被电-微调手艺”之后,他不仅背下了所有菜谱,还悟出了“中式烧烤”“日式烧鸟”这种更宏大的“美食哲学”。

- 梯度下降 (Gradient Descent) → “被电后微调手艺”这个动作。每次猜错都是一次负反馈,师傅会根据这个反馈,极其微小地调整他对“食材搭配”的判断,争取下次别再犯同样的错。
- 微调 (Fine-tuning) → “出师后的专场定制”。师傅手艺大成后,来了个大客户(我们用户)提要求:“以后我点的串儿,都得是‘低脂健康’风格的”。师傅不会去学新食材,他会调用脑子里已有的菜谱,专门给你组合出一套符合“低脂健康”指令的烤串儿。这就是指令微调。如果客户吃了还说“这个比那个更好吃”,师傅就会记住这个偏好,以后多给你烤你喜欢的,这就是RLHF(基于人类反馈的强化学习)。
02
把“黑话”翻译成大白话
现在,我们再回头看那些专业术语,就会发现它们其实没那么神秘。
1. 词向量 = “食材的风味档案”
它不是简单地给“苹果”标号1,给“香蕉”标号2。而是把“苹果”这个词,变成一个包含几百上千个数字的“坐标”,精确描述了它在“语义空间”里的位置。
在这个空间里,甚至可以进行数学运算,比如:
“国王”的向量 - “男人”的向量 + “女人”的向量 ≈ “女王”的向量
这就是为什么AI能理解类比,因为在它的世界里,万物皆可坐标化。
2. 自注意力机制 = “动态计算的亲密指数”
这东西是LLM核心架构的灵魂。为什么叫“自”注意力?因为它是在一句话内部自己跟自己玩连连看。它会给每个词发三个“身份牌”:
- Q (Query, 查询)
- K (Key, 键)
- V (Value, 值)
计算过程就像是,Q跟每个K进行“匹配度计算”,算出一个“亲密分”。然后用这个分数作为权重,把所有词的V值加权平均,得到一个融合了上下文关键信息的新形象。
3. 预训练 vs 微调 = “通识教育 vs 专科冲刺”
- 预训练是“读万卷书”,目标是建立对世界语言规律的广泛理解。它耗资巨大,就像让烧烤师傅烤遍宇宙万物。
- 微调是“行万里路”,目标是学会特定场景下的特定“说话方式”。比如,让模型学会扮演客服、写代码。它更经济高效,是大多数应用的基础。
03
一个颠覆你常识的真相
你以为LLM在做“阅读理解”,实际上它在做“高维几何”。
它不是通过逻辑推理来理解“因为…所以…”,而是发现“因为”这个词的向量出现后,跟着“所以”这个词的向量的概率,在几何上呈现出一种强烈的、可预测的模式。
这意味着,当数据量足够大、维度足够高时,统计相关性可以涌现出类似逻辑推理和知识创造的能力。
AI的“智能”不是人类意义上的“思考”,而是一种我们从未见过的、基于海量数据几何关系的“计算智能”。它正在重塑我们对“理解”和“创造”的定义。
04
如何正确地“使用”它
1. 什么时候它最管用?
- 处理模式化、有大量数据支撑的任务时,LLM是“YYDS”(永远的神)。比如文本总结、代码生成、语言翻译等。
- 当你的问题和它的“食谱库”(训练数据)高度重合时,它表现得像个专家。
2. 破除几个常见误解
- 误解:“AI有自己的观点。”
- 真相:“它只是在已有菜谱里做最优组合。” AI没有信念和情感,它的回答只是基于概率的最优输出。
- 误解:“可以直接教它新知识。”
- 真相:“想让它记住新东西,要么重新回炉(再训练),要么给它个小抄(检索增强,RAG)。” 在对话里告诉它的新事实,它转身就忘。
- 误解:“注意力权重图就代表了它的思考路径。”
- 真相:“那只是个‘参考’。” 权重高只能说明信息在计算中占比较大,但不等于唯一的因果解释。
既然LLM的“理解”,本质是高维空间里词与词之间的几何关系。
那我们人类的“理解”,在刨除掉喜怒哀乐这些感性体验后,剩下的纯粹理性部分,会不会也是我们大脑里某种更高级、更复杂的“神经烧烤”呢?
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。