



AI大语言模型(LLM)开发与训练入门
大语言模型(LLM)训练是指通过处理海量数据,教会人工智能模型理解和生成类人文本,从而显著提升其语言理解与生成能力。
引言
大语言模型(LLMs)彻底改变了我们与技术互动的方式,为自然语言处理(NLP)、人工智能和机器学习领域的进步提供了核心支撑。大语言模型的开发是一个复杂的过程,涉及将海量文本数据输入神经网络,使机器能够以前所未有的准确性理解和生成类人文本。近年来,大语言模型训练技术的不断进步催生了拥有数十亿参数的模型,这些模型能够胜任从连贯撰写文章到生成代码等广泛任务。
这些进展对各行各业产生了深远影响,正在重塑客户服务、内容创作乃至科学研究等领域。随着大语言模型持续演进,它们正不断改变我们与技术的交互方式,并为人工智能应用开辟全新前沿。本文将深入探讨大语言模型训练的技术细节,介绍前沿方法、面临挑战以及实际应用案例,帮助读者全面理解这一快速发展的领域。
什么是大语言模型(LLMs)?
语言模型的概念源于预测词语序列概率的思想,这从根本上增强了机器理解上下文和语义的能力。这类模型的发展历程中经历了多个重要里程碑:从基于规则的系统,到统计模型,再到如今以神经网络为主导的时代——尤其是Transformer模型,它利用深度学习技术,在语言理解和生成方面达到了前所未有的准确度。
大语言模型的核心在于,它们在由多种来源汇集而成的海量数据集上进行训练,从而学习语言模式、语法和用法的复杂细节。这种训练使模型能够执行各种基于语言的任务,模拟类似人类的理解能力,让人类与技术的交互变得更加自然和直观。
在下一节深入探讨大语言模型架构时,我们将解析支撑这些能力的结构组件,并阐明为何某些设计(如Transformer)已成为机器学习领域的基石。
揭秘大语言模型架构:训练的基础
大语言模型的神经网络基础
大语言模型建立在复杂的神经网络架构之上,旨在处理并生成类人文本。其核心采用深度学习技术,特别是通过多层神经网络来捕捉语言数据中的复杂模式。
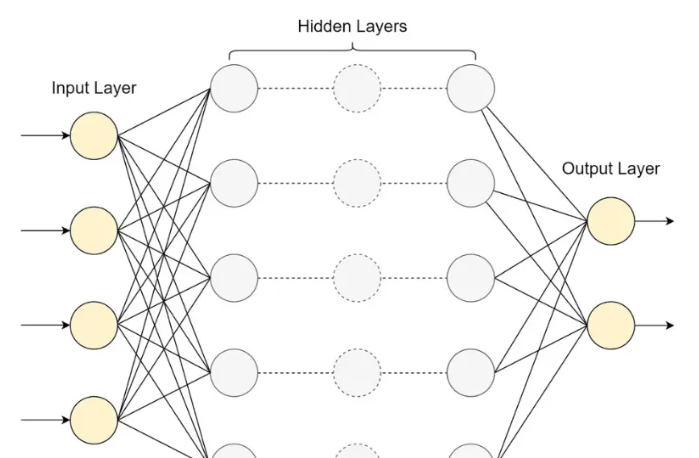
一个典型的大语言模型基本架构通常包括输入层、多个隐藏层和输出层。输入层接收经过分词(tokenized)处理的文本,随后数据在隐藏层中被逐步处理。正是这些隐藏层“施展魔法”——它们学习识别输入数据中的模式、上下文以及词语之间的关系。
下图是一个简化的大语言模型基本架构示意图:
在实际应用中,模型架构要复杂得多。现代大语言模型(LLMs)通常采用基于 Transformer 的架构,这种架构彻底革新了自然语言处理领域。以下是一个实现简化版基于 Transformer 的大语言模型结构的 Python 代码示例:
import torchimport torch.nn as nnclass SimpleLLM(nn.Module): def __init__(self, vocab_size, d_model, nhead, num_layers): super(SimpleLLM, self).__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.transformer = nn.Transformer(d_model, nhead, num_layers) self.fc_out = nn.Linear(d_model, vocab_size) def forward(self, src): embedded = self.embedding(src) output = self.transformer(embedded, embedded) return self.fc_out(output)# 示例用法model = SimpleLLM(vocab_size=30000, d_model=512, nhead=8, num_layers=6)这段代码定义了一个基础的基于 Transformer 的大语言模型,包含嵌入层(embedding layer)、Transformer 模块和输出层。其中,Transformer 模块是核心组件,利用自注意力机制(self-attention)来捕捉输入数据中的长距离依赖关系。
以下是上述 Python 代码的简明解释:
导入库:import 语句加载了构建神经网络所需的 PyTorch 模块。PyTorch 是一个流行的深度学习框架。torch 是其主模块,而 torch.nn 包含了构建神经网络的基本组件。
定义 SimpleLLM 类:
该类使用 PyTorch 定义了一个简单的大语言模型(LLM),继承自 nn.Module——这是 PyTorch 中所有神经网络模块的基类,提供了通用功能支持。
构造函数 __init__ 参数说明:
vocab_sized_modelnheadnum_layers
构造函数内部组件:
self.embeddingself.transformerself.fc_out
前向传播方法(forward):
srcembeddedoutput- 最终输出通过 fc_out 层生成,用于预测序列中的下一个词元。
示例用法:
底部的代码创建了一个 SimpleLLM 实例,指定了词汇表大小、嵌入维度、注意力头数和层数。这个实例(model)代表一个已配置好的神经网络,可直接用于训练或推理。
大语言模型 vs. 循环神经网络(RNNs)
将基于 Transformer 的架构与循环神经网络(RNNs)进行比较,可以发现以下几个关键差异:
- 并行化能力
- 长距离依赖建模
- 位置编码
- 训练稳定性
正是这些架构上的优势,使基于 Transformer 的模型成为现代大语言模型的首选,使其在各类自然语言处理任务中达到最先进的性能。
注意力机制与自注意力(Self-Attention)
注意力机制是现代大语言模型的关键组成部分,使模型在处理或生成文本时能够聚焦于输入中的相关部分。在基于 Transformer 的架构中,核心是自注意力机制,它允许序列中的每个元素关注序列中的所有其他元素,从而无论距离远近都能捕捉复杂的依赖关系。
自注意力机制主要基于三个组件:查询(Query, Q)、键(Key, K) 和 值(Value, V)。这些组件通过对输入序列进行线性变换得到。注意力权重通过以下公式计算:
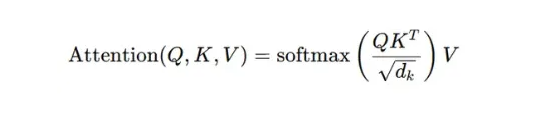
其中:
Q、K 和 V
分别是代表查询(Queries)、键(Keys)和值(Values)的矩阵;
dₖ
是键向量的维度;
√dₖ
是一个缩放因子,用于防止点积结果过大。
该过程可分为以下几个步骤:
- 计算查询(Query)与所有键(Key)的点积;
- 将结果除以 √dₖ 进行缩放;
- 应用 softmax 函数,得到注意力权重;
- 将这些权重与值(Value)相乘,得到最终输出。
在实际应用中,大语言模型采用**多头注意力(Multi-Head Attention)**机制,即并行地多次执行上述过程:
多头注意力公式(Multi-Head Formula):
其中每个注意力头(head)的计算方式为:
单个注意力头公式(Head-i Formula):
注意力机制对大语言模型性能的影响极为深远:
长距离依赖建模
:注意力机制使模型能够捕捉文本中任意距离词语之间的关系,克服了传统序列模型的局限性。
并行化能力
:与循环模型不同,注意力操作可完全并行计算,显著加快训练和推理速度。
可解释性
:通过可视化注意力权重,可以直观理解模型在执行不同任务时关注输入的哪些部分。
灵活性
:同一套注意力机制可广泛应用于各类自然语言处理任务,如机器翻译、文本摘要等。
性能可扩展性
:注意力机制推动了更大、更强语言模型的发展,模型性能随规模扩大而持续提升
通过利用注意力机制,大语言模型(LLMs)能够更深入地理解输入文本中的上下文及其内部关系,从而在各类语言任务中生成更加连贯且符合语境的输出。
分词与嵌入策略
分词(Tokenization) 是大语言模型训练中至关重要的预处理步骤,它将输入文本拆分为称为“词元”(tokens)的更小单元。这些词元构成了语言模型处理和生成文本的基本构件。目前两种广泛使用的分词方法是 字节对编码(Byte Pair Encoding, BPE) 和 WordPiece。
- BPE 是一种迭代算法,从单个字符开始,逐步合并出现频率最高的相邻词元对,直到达到预设的词汇表大小。该方法在词汇表规模与表示罕见词或子词(subword)的能力之间取得了有效平衡。
- WordPiece 由 Google 开发,与 BPE 类似,但采用略有不同的合并标准:它选择那些在当前词汇表下能最大化训练数据似然度的合并操作。这种方法倾向于保留语言中常见且具有实际意义的词和子词。
其他分词方法还包括:
- 字符级分词(Character-level tokenization)
- 词级分词(Word-level tokenization)
- SentencePiece
文本完成分词后,需使用嵌入(Embedding)技术将词元转换为稠密向量表示,以捕捉其语义关系。词嵌入在大语言模型训练中起着关键作用,为模型提供可计算的、富含语义信息的数值表示。
常见的嵌入技术包括:
- Word2Vec
- GloVe(Global Vectors for Word Representation)
- FastText
- 上下文嵌入(Contextual Embeddings)
以下是不同分词与嵌入方法的对比表:
| 方法 | 分词方式 | 嵌入技术 | 优势 | 局限性 |
|---|---|---|---|---|
| BPE + Word2Vec | Byte Pair Encoding | Word2Vec | 能处理罕见词,词汇效率高 | 嵌入固定,缺乏上下文感知 |
| WordPiece + GloVe | WordPiece | GloVe | 平衡常见词与罕见词,捕捉全局统计特征 | 嵌入固定,需大规模语料 |
| SentencePiece + FastText | SentencePiece | FastText | 语言无关,有效处理 OOV 词 | 可能产生不直观的子词 |
| 字符级 + ELMo | 字符级 | ELMo(上下文嵌入) | 无 OOV 问题,可捕捉词形结构 | 词汇量大,计算开销高 |
| BPE + BERT | Byte Pair Encoding | BERT(上下文嵌入) | 动态嵌入,强上下文感知能力 | 计算密集,需微调 |
分词与嵌入策略的选择对大语言模型性能有显著影响。目前,BPE 或 WordPiece 配合 BERT 等上下文嵌入已成为最先进模型的主流方案,在词汇规模、罕见词处理和上下文感知表示之间取得了良好平衡。然而,最佳选择仍取决于具体任务、目标语言以及可用的计算资源。
前沿训练技术:突破大语言模型的边界
预训练策略
预训练(Pre-training) 是大语言模型开发的关键阶段,模型在此阶段通过海量无标注文本数据学习通用的语言理解能力。该过程依赖无监督学习技术,为后续的下游任务奠定基础。
掩码语言建模(Masked Language Modeling, MLM) 是 BERT 等模型采用的核心预训练方法。在 MLM 中,输入序列中约 15% 的词元被随机遮盖(mask),模型需预测这些被遮盖的词元。这一设计迫使模型深入理解文本的上下文及双向依赖关系。MLM 的目标函数可表示为:
其中,x是来自数据集D的一个序列,x_masked和x_observed分别表示被遮盖的词元和未被遮盖(可见)的词元。
下一句预测(Next Sentence Prediction, NSP) 是另一种常与 MLM 联合使用的预训练任务。在 NSP 中,模型会接收两个句子,并需要判断第二个句子在原始文本中是否紧接在第一个句子之后。该任务有助于模型理解句子之间的关系以及更长距离的篇章结构。NSP 损失通常表示为:
其中,( s_1 ) 和 ( s_2 ) 是两个句子,而 (IsNext(s_1, s_2) ) 是一个二元指示变量,用于表示在原始文本中 ( s_2 ) 是否紧接在 ( s_1 ) 之后。
其他预训练方法包括:
- 因果语言建模(Causal Language Modeling, CLM):CLM 是生成式预训练模型(如 GPT,即 Generative Pre-trained Transformer)所采用的技术。该方法仅基于序列中前面的词元来预测下一个词元。这种单向、顺序式的建模方式使模型能够根据给定提示生成逻辑连贯的文本,模拟人类的语言生成过程。由于 CLM 能够实时生成连贯且符合语境的续写内容,因此特别适用于聊天机器人、创意写作工具和交互式人工智能系统等文本生成任务。然而,CLM 不利用后续词元的信息,这在需要深度双向上下文理解的任务中可能构成局限。
- 片段预测(Span Prediction):预测被遮盖的较长文本片段,如 SpanBERT 模型所采用的方法。
- 替换词元检测(Replaced Token Detection):区分原始词元与被替换的词元,如 ELECTRA 模型所使用的方法。
这些预训练策略的核心思想是自监督学习(Self-supervised learning)。它允许模型从未标注的数据中自动生成监督信号,形成一种“伪标签”机制。在大语言模型的背景下,自监督学习使模型无需依赖昂贵且规模有限的人工标注数据集,即可学习到丰富的语言表征。
常见的预训练数据集及其特点包括:
- Common Crawl:一个大规模网络爬取数据集,包含数 PB 的数据。
- Wikipedia:高质量、经过人工整理的百科知识数据集。
- BookCorpus:大量未出版书籍的集合。
- OpenWebText:受 WebText 启发、通过网络抓取构建的数据集。
这些数据集通常组合使用,为大语言模型提供广泛的语言知识基础,使其能在各种任务和领域中实现良好泛化。预训练数据集的选择与预处理对模型性能及潜在偏见具有重大影响,是大语言模型开发中的关键考量因素。
针对特定任务微调大语言模型
微调(Fine-tuning) 是将预训练的大语言模型适配到特定任务或领域的重要步骤。该过程通过在较小的、任务专用的数据集上进一步训练预训练模型,以优化其在目标应用上的表现。
典型的微调流程包括以下步骤:
- 数据集准备
- 模型初始化
- 添加任务特定层
- 超参数选择
- 训练循环
- 评估与迭代
提示工程(Prompt engineering) 对于最大化生成模型的效果至关重要,需要精心设计提示语,以有效引导人工智能的生成过程。
迁移学习(Transfer learning) 是一种机器学习技术,指将在某一任务上训练好的模型作为起点,用于另一个相关任务的模型开发。微调正是基于这一原理:将预训练模型进一步调整,以适应新的、通常更具体的目标任务。这种方法利用了源任务与目标任务之间的共性特征,从而减少对大量新任务标注数据和计算资源的需求。
当目标任务领域的数据量有限时,迁移学习尤为有用,因为它能显著提升学习效率和预测准确率,借助先前相关任务中学到的知识。如今,迁移学习已成为自然语言处理和计算机视觉等领域的标准技术——例如,将 BERT 或 ResNet 等预训练模型适配到情感分析、物体识别甚至医学影像诊断等任务中。在大语言模型开发中,迁移学习具有以下优势:
- 降低数据需求
- 加速收敛
- 提升泛化能力
- 高适应性
有效的微调最佳实践包括:
- 根据预训练领域与目标任务的相似性,谨慎选择预训练模型;
- 使用比预训练阶段更低的学习率,以保留已学知识;
- 在小型任务数据集上实施早停(early stopping),防止过拟合;
- 考虑冻结预训练模型的部分层(尤其是底层),以保留通用语言理解能力;
- 尝试不同的微调策略,如渐进解冻(gradual unfreezing)或差异性微调(discriminative fine-tuning);
- 定期在预留验证集上评估性能,监控过拟合风险;
- 使用任务特定的评估指标,而非仅依赖损失值;
- 采用数据增强技术,提升微调数据集的多样性;
- 在处理多个相关任务时,考虑多任务微调以提升整体性能;
- 在微调时长与灾难性遗忘风险之间保持谨慎平衡。
高级优化算法
优化算法在大语言模型训练中起着至关重要的作用,显著影响模型的收敛速度和最终性能。诸如 Adam 和 AdamW 等前沿技术因其能高效处理大规模稀疏数据集,已成为大语言模型开发中的标准工具。
Adam(Adaptive Moment Estimation) 结合了 RMSprop 和动量优化的思想。它利用梯度的一阶矩(均值)和二阶矩(未中心化的方差)估计,为每个参数自适应地调整学习率。Adam 的参数更新规则如下:
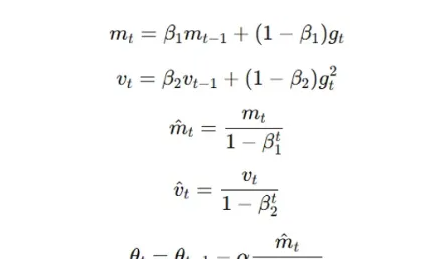
其中,( g_t ) 是时刻 ( t ) 的梯度,( m_t ) 和 ( v_t ) 分别是一阶矩和二阶矩的估计值,( \beta_1 ) 和 ( \beta_2 ) 是衰减率,( α ) 是学习率,( ε ) 是一个用于数值稳定的小常数。
AdamW 是 Adam 的一种变体,通过将权重衰减(weight decay)与梯度更新解耦,解决了 Adam 中 L2 正则化存在的问题。AdamW 的改进如下:
其中,(λ) 是权重衰减系数。
学习率调度(Learning rate schedules)对于大语言模型(LLM)的训练优化至关重要。它们在训练过程中动态调整学习率,以提升模型的收敛速度和泛化能力。常见的调度策略包括:
- 阶梯式衰减(Step Decay)
- 余弦退火(Cosine Annealing)
- 线性预热(Linear Warmup)
- 循环学习率(Cyclical Learning Rates)
以下是一个使用 PyTorch 实现 Adam 优化器并结合学习率调度的 Python 代码示例:
import torchfrom torch.optim import Adamfrom torch.optim.lr_scheduler import CosineAnnealingLR# 模型定义model = YourLLMModel()# Adam 优化器optimizer = Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-8)# 余弦退火学习率调度器scheduler = CosineAnnealingLR(optimizer, T_max=100, eta_min=1e-5)# 训练循环for epoch in range(num_epochs): for batch in dataloader: optimizer.zero_grad() loss = compute_loss(model, batch) loss.backward() optimizer.step() # 更新学习率 scheduler.step() current_lr = scheduler.get_last_lr()[0] print(f"Epoch {epoch}, Learning Rate: {current_lr:.6f}")这段代码设置了初始学习率为 0.001 的 Adam 优化器,并应用了余弦退火调度策略。学习率将在 100 个 epoch 内平滑下降至最小值 (1e-5)。
若使用 AdamW,只需将优化器初始化部分替换为:
from torch.optim import AdamWoptimizer = AdamW(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-8, weight_decay=0.01)这些先进的优化技术与合适的学习率调度相结合,能够显著提升 LLM 的训练效率,加快收敛速度并改善模型性能。
克服训练障碍:应对大语言模型的挑战
计算资源管理
由于大语言模型规模庞大且需处理海量数据,其训练过程对计算资源要求极高。主要硬件包括图形处理器(GPU)、张量处理器(TPU)和华为昇腾处理器(NPU)。
专为深度学习设计的 GPU(如 NVIDIA 的 A100 或 V100)被广泛用于 LLM 训练,具备高内存带宽和数千个并行处理核心。而 Google 开发的 TPU 和华为开发的昇腾NPU是专用于机器学习任务的定制芯片(ASIC),在矩阵运算方面表现卓越,特别适合 LLM 训练。
选择 GPU 还是 TPU 或 NPU 通常取决于可用性、成本及具体模型需求。许多机构倾向于采用云服务,以较低的前期投入获得高性能硬件资源。
分布式训练技术对于应对 LLM 的计算需求至关重要。该技术可将训练任务分配到多个设备或机器上,大幅缩短训练时间。常见方法包括:
- 数据并行(Data Parallelism)
- 模型并行(Model Parallelism)
- 流水线并行(Pipeline Parallelism)
实现分布式训练通常需借助专用库或框架。例如,PyTorch 提供 DistributedDataParallel 支持数据并行,而 DeepSpeed 和 Megatron-LM 等库则提供更高级的分布式训练功能。
以下是一个使用 PyTorch 实现数据并行的基本示例:
import torch.multiprocessing as mpimport torch.distributed as distfrom torch.nn.parallel import DistributedDataParallel as DDPdef setup(rank, world_size): dist.init_process_group("nccl", rank=rank, world_size=world_size)def cleanup(): dist.destroy_process_group()def train(rank, world_size): setup(rank, world_size) model = YourLLMModel().to(rank) ddp_model = DDP(model, device_ids=[rank]) # 此处添加训练循环 cleanup()if __name__ == "__main__": world_size = 4 # GPU 数量 mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)尽管搜索结果中未提供具体的性能对比数据,下表展示了不同硬件配置在 LLM 训练中的假设性比较:
| 硬件配置 | 相对训练时间 | 相对成本 | 能效 | 可扩展性 |
|---|---|---|---|---|
| 单 GPU (V100) | 1.0x | $ | 中等 | 低 |
| 多 GPU (4×V100) | 0.3x | $$$ | 中等 | 中等 |
| TPU v3-8 | 0.2x | $$ | 高 | 高 |
| GPU 集群 (16×A100) | 0.1x | $$$$ | 低 | 极高 |
| TPU v4-32 | 0.05x | $$$$$ | 极高 | 极高 |
注:实际性能和成本会因具体模型、数据集和实现细节而异。
偏见与公平性问题
大语言模型中的偏见可能导致不公平甚至歧视性输出,因此在 LLM 开发中,偏见检测与缓解至关重要。偏见通常源于训练数据中存在的不平衡或社会偏见,模型会学习并可能放大这些问题。
偏见检测方法包括:
- 统计分析
- 词嵌入分析
- 情感分析
- 主题建模
- 基于人类反馈的强化学习(RLHF)
缓解偏见的多维度策略:
- 数据增强
- 样本重加权
- 对抗去偏(Adversarial Debiasing)
- 使用去偏数据集进行指令微调
多样性和代表性的数据集至关重要,因为它们能够:
- 减少系统性偏见与刻板印象
- 提升模型在不同人群中的表现
- 增强模型理解和生成多元内容的能力
- 降低模型放大社会偏见的风险
构建多样化数据集的建议:
- 从不同地理区域和文化背景采集数据
- 包含不同时代的内容
- 确保性别、年龄、种族、社会经济背景等方面的均衡代表
- 在争议性话题中纳入多元观点
- 为非英语使用者纳入翻译文本和多语言数据,扩大受众覆盖
- 定期对数据集进行多样性与代表性审计,主动识别偏差或缺口
偏见评估指标示例:
人口均等性(Demographic Parity, DP)
:该公平性指标衡量模型对不同受保护群体(如性别、种族)给出有利预测的概率是否一致。计算方式为受保护群体与非受保护群体获得正向预测概率的绝对差值。DP 强调“平等对待”,即无论真实结果如何分布,模型不应偏向任一群体。
其中,(Ŷ) 表示模型的预测结果,(A) 为受保护属性(如性别、种族等)。该指标值越低,表明偏见越小。
机会均等(Equal Opportunity, EO):
该指标特别关注在真正应获得正向结果的人群中,不同群体获得正向预测的公平性。它比较的是:在真实结果为正的前提下,模型对不同受保护属性群体给出正向预测的概率是否一致。具体计算方式为,在真实结果为正的条件下,受保护群体与非受保护群体获得正向预测概率之间的绝对差值。这一指标确保当个体确实应获得正向结果时,所有群体都有平等的机会被模型正确预测为正向,从而聚焦于“机会平等”。
其中,(Y) 为真实标签。该指标值越接近零,表明机会越平等。
差异影响(Disparate Impact, DI):DI 衡量由受保护属性定义的不同群体之间获得有利结果的比例,旨在检测这些群体在待遇上是否存在显著差异。其计算方式为取以下两个比率中的较小值:
- 非受保护群体获得正向预测的概率与受保护群体获得正向预测的概率之比。
该值越接近 1,表示群体间的差异越小,说明两个群体以相近的比率获得有利结果,这是公平性的理想状态。
词嵌入关联测试(Word Embedding Association Test, WEAT):WEAT 通过比较两组目标词((X) 和 (Y))与两组属性词((A) 和 (B))之间的相对相似性,来衡量词嵌入中的偏见。该测试计算以下均值余弦相似度之差:
- 属性词集 (A) 与目标词集 (X) 和 (Y) 的平均余弦相似度;
- 属性词集 (B) 与目标词集 (X) 和 (Y) 的平均余弦相似度。
结果量化了每个目标词集与各属性词集之间的关联强度。绝对值越大,表明偏见越强,揭示出某些词语可能更倾向于与特定属性相关联。该指标有助于识别和量化语言模型中隐含的刻板偏见。
其中,(A) 和 (B) 为属性词集,(X) 和 (Y) 为目标词集。绝对值越大,表示偏见越显著。
解读这些指标需要结合具体情境并谨慎判断。例如,在某些应用场景中,人口均等性(DP)为 0.1 可能被视为较低偏见,但在其他对公平性要求更高的场景中则可能被认为过高。因此,必须根据具体用例及模型决策可能带来的社会影响,设定合理的阈值。
结合定性分析和现实世界测试,定期使用上述指标评估大语言模型,有助于持续监控并改进模型输出的公平性。
缩放定律与模型规模考量
大语言模型(LLM)的性能与模型规模、数据集规模之间的关系遵循某些经验观察到的缩放定律(Scaling Laws)。通常,同时增大模型规模和数据集规模会带来性能提升,但收益会逐渐递减。
LLM 的性能通常与模型规模和数据集规模呈幂律关系(power law),可表示为:
其中,(L) 表示损失(即性能的反向指标),(N) 为模型参数数量,(C) 是与数据集规模相关的常数,(\alpha) 为缩放指数(对于语言模型,通常约为 0.7)。
随着模型规模不断增大,要实现性能的线性提升,所需的数据量呈指数级增长。这种关系可如下图所示:
训练和部署超大规模模型所面临的挑战包括:
- 计算资源
- 内存限制
- 训练不稳定性
- 推理延迟
- 能耗问题
- 过拟合风险
计算需求随模型规模增长的关系可表示如下:

尽管存在上述挑战,研究人员仍在不断突破模型规模的极限。例如,GPT 和 PaLM 等模型已证明,将参数规模扩展至数千亿甚至上万亿级别,能够涌现出小模型所不具备的新能力。
为了在模型规模、性能和实际约束之间取得平衡,数据科学家、研究人员和工程师在设计与部署大语言模型(LLM)时,必须仔细权衡具体应用场景的需求与可用资源。
超越这一讨论,近期大语言模型的发展方向出现了新的转变。OpenAI 的 o1 模型便是一个典型例子——它通过试错学习,利用过往经验来优化未来的决策。这种策略特别强调在推理阶段进行更深入的“思考”,使模型在输出答案前能够对问题进行充分分析与推理。
2024 年 8 月,Google DeepMind 与加州大学伯克利分校联合发表的一篇论文支持了这一思路,指出在测试阶段增加计算资源(即“测试时计算”,test-time compute)可能比单纯扩大模型规模更有效。研究发现,在某些初始表现尚可的任务中,一个较小的模型若在测试时配备额外的计算资源,其性能甚至可以超过规模达其 14 倍的大模型。这一方向的可能性几乎是无限的。
实际应用:大语言模型的落地场景
自然语言处理任务(NLP)
大语言模型彻底革新了众多自然语言处理任务,在广泛应用中实现了最先进的性能。其中两个突出的例子是机器翻译和文本摘要。
在机器翻译领域,基于 Google Transformer 架构的神经机器翻译(NMT)系统取得了显著成果。在 WMT’14 英译法任务中,该模型 BLEU 得分为 41.8,超越了人类水平;在英译德任务中,BLEU 得分达到 28.4,刷新了该领域的基准。
文本摘要方面,LLM 同样取得了重大进展。例如,PEGASUS 模型在 12 个摘要数据集上均达到当时最佳水平。在 CNN/DailyMail 数据集上,其 ROUGE-1 得分为 44.17,ROUGE-2 为 21.47,ROUGE-L 为 41.11,展现出生成高质量摘要的强大能力。
LLM 在其他 NLP 任务中也表现出色。例如,在问答任务中,T5 模型在 SQuAD 2.0 数据集上的 F1 分数达到 92.5;在情感分析任务中,RoBERTa 在 SST-2 数据集上的准确率达到 96.4%。
以下是常见 NLP 任务及其对应的评估指标:
机器翻译
:BLEU(Bilingual Evaluation Understudy)、METEOR(Metric for Evaluation of Translation with Explicit Ordering)、TER(Translation Edit Rate)
文本摘要
:ROUGE(Recall-Oriented Understudy for Gisting Evaluation)、BLEU、BERTScore
问答系统
:Exact Match(EM)、F1 Score、Mean Reciprocal Rank(MRR)
命名实体识别
:F1 Score、Precision、Recall
情感分析
:Accuracy、F1 Score、AUC-ROC(Area Under ROC Curve)
文本分类
:Accuracy、F1 Score、Precision、Recall
自然语言推理
:Accuracy、F1 Score
共指消解
:MUC、B³、CEAFe
对话系统
:BLEU、Perplexity、人工评估指标
文本生成
:BLEU、METEOR、ROUGE、Perplexity、人工评估
词性标注
:Accuracy、F1 Score
语义角色标注
:F1 Score、Precision、Recall
语法错误纠正
:F₀.₅ Score、GLEU(General Language Evaluation Understanding)
复述生成
:BLEU、METEOR、TER、PIC(Paraphrase In Context)得分
这些指标为模型性能提供了量化衡量标准,有助于研究人员和从业者比较不同方法并追踪领域进展。然而需注意的是,许多 NLP 任务仍需结合人工定性评估,尤其对于流畅性、连贯性和语境适切性等难以被自动指标完全捕捉的维度。
代码生成与分析
大语言模型已成为软件开发中的强大工具,具备代码补全、测试用例生成、缺陷检测乃至完整代码生成等能力。这些模型利用对编程语言及模式的理解,协助开发者完成各类任务。
代码补全是 LLM 在软件开发中的主要应用之一,并已取得显著进展。例如,由 OpenAI Codex 驱动的 GitHub Copilot 能根据上下文和注释建议完整的函数或代码块。给定一个函数签名和描述性注释,Copilot 常能高准确率地生成完整实现。
在缺陷检测方面,LLM 同样表现出色。它们可分析代码片段,识别从语法错误到逻辑漏洞的各类潜在问题。例如,AI 驱动的代码审查工具 DeepCode 通过学习数百万个开源仓库,能够检测 bug 并提出修复建议。
然而,面向代码的 LLM 也面临若干挑战与局限:
- 上下文理解不足
- 安全风险
- 许可问题
- 过度依赖
- 幻觉问题
尽管如此,多个成功的代码生成应用已涌现:
- TabNine
- GPT-4 用于自然语言转 SQL
- Codex 用于 API 使用
- AlphaCode
- Replit GhostWriter
这些应用展示了 LLM 革新软件开发实践的巨大潜力,可显著提升生产力与可及性。但关键在于审慎使用这些工具,充分认识其局限,并辅以人类的专业判断与监督。
创意与内容生成
生成式人工智能(GenAI),如大语言模型,已彻底改变创意写作与内容创作,其能力涵盖从营销文案生成到诗歌创作,甚至剧本编写。这些模型能以多种风格和格式产出类人文本,常展现出惊人的连贯性与创造力。
在内容营销领域,GPT-3 等模型被用于生成博客文章、社交媒体内容和产品描述。例如,AI 写作助手 Jasper.ai 能就指定主题撰写完整文章,极大加速内容生产流程。在新闻业,Articoolo 等 AI 工具可根据基本信息自动生成新闻稿,尽管事实核查和编辑决策仍需人工介入。
LLM 在创意写作方面也表现卓越。它们可创作短篇小说、诗歌,甚至辅助剧本写作。例如,GPT 已被用于合作编写短片剧本,展现出对叙事结构和对话模式的理解与复现能力。
然而,AI 在创意与内容生成中的应用也引发诸多伦理考量:
- 作者身份与版权
- 抄袭与原创性
- 岗位替代
- 虚假信息与伪造内容
- 创意真实性
- 合规监管
知名 LLM 的创意输出示例包括:
- GPT 诗歌
- BERT 短篇小说
- InferKit 剧本
- AIVA 歌词
- Copy.ai 营销文案
尽管 LLM 为增强人类创造力与生产力提供了强大工具,但其伦理挑战也迫切要求我们在创意领域负责任地开发与使用这些技术。
结论
大语言模型已彻底革新自然语言处理,在各类任务中展现出非凡能力。从机器翻译到创意写作,LLM 展现了其多功能性与强大性能。这些模型的训练过程涉及注意力机制、先进优化算法以及对计算资源的精细管理等复杂技术。
偏见缓解与缩放定律等问题仍是当前研究的重点。随着 LLM 训练技术的持续演进,我们有望看到模型在性能、效率和适用性方面的进一步提升。少样本学习、多模态模型以及更高效的训练范式等方向的研究,预示着更加激动人心的发展前景。鉴于人工智能领域正以前所未有的速度进步,工程及相关从业者保持对这些进展的关注至关重要。
常见问题解答(FAQ)
Q:大语言模型的“训练”和“微调”有何区别?
A:训练(通常称为预训练)是指使用大规模、多样化的数据集教会模型理解和生成语言,从而构建一个具备广泛语言理解能力的通用模型。而微调则是在预训练模型基础上,使用更小的、特定任务的数据集进行进一步训练,使其适应具体应用场景。
- 预训练适用于从零开始构建新模型或追求通用语言理解能力;
- 微调适用于将现有模型适配到特定任务或领域。
预训练的优势在于具备广泛的泛化能力,但需要大量计算资源和数据;微调则能快速适配特定任务,少量数据即可获得高性能,但可能存在灾难性遗忘风险,且需精细调整超参数。
Q:训练一个大语言模型通常需要多长时间?
A:训练时间因模型规模和硬件配置差异巨大。以下为参考对比:
| 模型规模 | 硬件配置 | 近似训练时间 |
|---|---|---|
| 10 亿参数 | 8 块 V100 GPU | 2–3 周 |
| 100 亿参数 | 64 块 V100 GPU | 1–2 个月 |
| 1000 亿参数 | 512 块 V100 GPU | 3–6 个月 |
| 1 万亿参数 | 2048+ 块 V100 GPU | 6–12 个月 |
影响训练时长的因素包括:
- 模型架构与复杂度
- 数据集质量、规模及预处理需求
- 硬件效率与并行策略
- 优化算法与学习率调度
- 收敛标准与早停策略
Q:训练多语言大语言模型的主要挑战有哪些?
A:多语言 LLM 训练面临多重复杂性:
- 数据不平衡
- 跨语言迁移
- 分词策略
- 模型容量
提升多语言性能的技术包括:
- 使用语言无关的分词器(如 SentencePiece)
- 引入语言特定适配器或监督微调(SFT)
- 采用多语言预训练目标
- 应用跨语言数据增强技术
成功的多语言 LLM 项目包括:
- Google 的 mBERT(支持 104 种语言)
- Meta(Facebook)的 XLM-R(在多种语言上超越单语模型)
- mT5(T5 的多语言版本,在 101 种语言上表现优异)
优化 AI 工作流对于扩展应用规模、应对日益复杂的机器学习项目至关重要。
Q:什么是检索增强生成(RAG)?它如何提升 AI 模型能力?
A:检索增强生成(Retrieval-Augmented Generation, RAG)是一种将语言模型与检索系统结合的 AI 技术。该系统能根据用户查询从大型数据库或知识库中检索相关信息,RAG 则利用这些信息生成更准确、更具深度的回答。该方法在问答系统和内容生成等场景中尤为有效,因为接入外部详细信息可显著提升回答的相关性与丰富度。
Q:哪些公司在人工智能领域处于领先地位?有哪些由主流公司开发的代表性大语言模型?
A:
- Google DeepMind虽以强化学习突破闻名,但在大语言模型(LLM)领域贡献了BERT模型。BERT通过双向编码器表征技术,在句子中理解词语与上下文的复杂关系,彻底革新了机器对人类语言的理解方式。OpenAI其GPT系列模型是全球最著名的大语言模型之一,以在广泛主题上生成连贯、语境相关文本的能力著称。GPT的通用性使其适用于写作辅助、编程帮助、数据分析等复杂任务,持续推动LLM技术边界。IBM利用Watson技术开发了面向专业领域的先进LLMs,应用于客户服务和医疗保健。Watson能高效筛选海量数据,提供行业洞察并生成自动化响应,成为企业级AI解决方案的标杆。微软推出Turing-NLG等大规模语言模型,通过深度学习生成类人文本,显著增强Office文档翻译、Azure认知服务及Teams智能助手功能,构建了企业级AI应用生态。Meta(原Facebook)LLaMA系列模型(LLaMA 2/3.1)专为多任务NLP设计,覆盖翻译、内容生成与摘要等场景,以高效架构著称。其开源策略推动了学术界与工业界的模型轻量化研究热潮。亚马逊除消费级Alexa外,Amazon Comprehend作为NLP服务,基于LLMs从文本中挖掘语义关联,为金融、医疗等行业提供语言定制化分析,实现商业洞察与合规审查。百度推出ERNIE Bot系列模型,在中文语义理解与生成任务中表现卓越。支持文心一言等产品,覆盖内容创作、智能客服及代码生成,通过飞桨框架实现产业智能化升级。阿里巴巴通义千问(Qwen)系列模型以多语言支持与代码写作能力为核心,赋能通义万相、通义听悟等产品,通过魔搭平台开放模型生态,推动电商、金融等垂直领域创新。腾讯混元(HunYuan)大模型整合视觉、文本与语音多模态能力,在跨模态检索、对话生成等任务中突破,支撑企业微信、腾讯广告等场景,实现AI技术的规模化商业落地。华为盘古大模型系列聚焦行业应用,涵盖NLP、计算机视觉与科学计算领域。通过ModelArts平台提供全流程开发工具,助力政务、制造、能源等行业实现智能化转型。DeepSeek作为中国新兴LLM领军企业,DeepSeek推出DeepSeek V2等超大规模语言模型(参数量超2000亿),以多语言支持、代码生成与长文本推理能力为核心优势。其模型通过混合专家(MoE)架构实现高效训练,已应用于商业智能、科研辅助及教育领域,支持企业级API定制与私有化部署。
Q:大语言模型(LLMs)相关的环境问题有哪些?
A:大语言模型消耗大量能源,导致碳排放增加。例如,根据不同的来源,向 ChatGPT 提出一次查询可能排放 2.5 至 5 克二氧化碳。一项详尽的计算表明,每条发送给 ChatGPT 的消息大约产生 4.32 克二氧化碳。
为使大语言模型的训练更加环保,业界已采取以下措施:
- 开发更高效的模型架构,如 Performer 或 Reformer
- 在训练任务中采用碳感知调度(carbon-aware scheduling)
- 应用稀疏化(sparsity)和剪枝(pruning)技术以减少计算量
- 在数据中心使用可再生能源
减少环境影响的建议包括:
- 在可行的情况下,优先考虑模型效率而非单纯追求模型规模
- 重用并微调现有模型,而非从头开始训练
- 投资能效更高的硬件
- 在人工智能项目中实施碳足迹追踪与报告
- 推动共享模型的合作,以减少重复训练带来的资源浪费
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。