



最强多模态大模型Gemini 3 Pro强在哪里?

近期,谷歌又公布了Gemini 3 Pro在视觉基准测试上的表现,它在 MMMU Pro 和 Video MMMU 等视觉基准测试上都取得了新的最高成绩,特别是在复杂视觉推理方面。同时它在面向具体应用的评测中(例如文档、空间、屏幕以及长视频理解)同样表现突出。
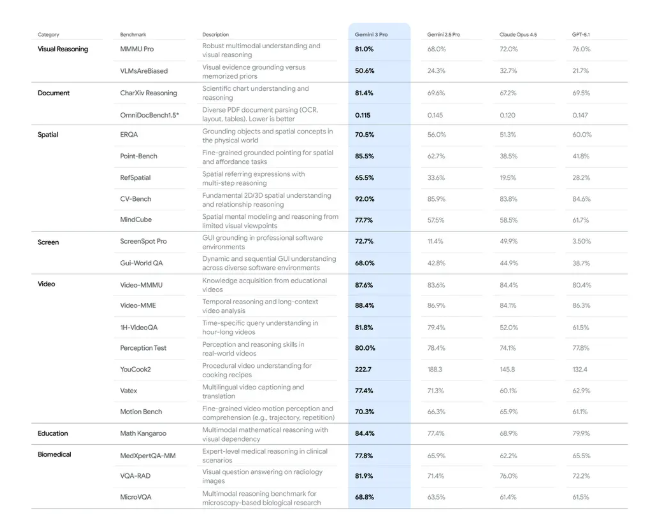
而且,在Vision Arena排行榜上,目前Gemini 3 Pro的Elo得分超过了1300,排行第一。所以无论从客观评测还是主观评测的结果来看,Gemini 3 Pro都是现在当之无愧的最强多模态大模型。
那么,Gemini 3 Pro的多模态能力到底强在哪里呢?官方给了一些具体的例子。
文档理解
真实世界的文档往往杂乱、无结构,而且很难解析,通常包含交错的图片、难以辨认的手写文本、嵌套表格、复杂数学符号以及非线性的版式布局。Gemini 3 Pro 在这一领域实现了显著跃升,覆盖整个文档处理流程,并具备极高精度的 OCR 能力以及复杂的视觉推理能力。
想要真正理解一个文档,模型必须能够在噪声和格式多变的情况下,准确检测并识别文本、表格、数学公式、图形与图表。一个核心能力是 “反渲染(derendering)”:即把视觉文档逆向还原为能够重建内容的结构化代码(HTML、LaTeX、Markdown)。正如下面的示例所示,Gemini 3 展现了跨模态的精准感知能力,比如把一份 18 世纪的商人账记录转成复杂表格,或将带数学标注的原始图像转成精确的 LaTeX 代码。
而且 Gemini 3 Pro 还可以在表格与图表上执行复杂的、多步骤推理(模型在 CharXiv Reasoning 基准上显著优于人类基线-80.5%)。
下面是模型分析一份62页的美国人口普查局报告,使用的提示词如下:
“比较 2021–2022 年间『货币收入(Money Income)』与『税后收入(Post-Tax Income)』的基尼系数百分比变化,解释导致税后指标出现分歧的原因;就『货币收入』而言,最低五分位的份额是上升还是下降?”
模型会首先通过视觉提取在图 3 中找到“货币收入下降 1.2%”的信息,并与表 B-3 中“税后收入上升 3.2%”的数据进行交叉引用;随后运用因果逻辑,将这一差异与文本中的政策因素相关联,准确识别出 ARPA 政策到期和刺激支付结束是导致分化的主要原因;继而在数值比较中,通过查阅表 A-3 并对 2.9 与 3.0 进行比对,得出最低五分位家庭收入占比呈上升趋势的结论;最后再给出回答。
空间理解
Gemini 3 Pro 也是目前空间理解能力最强的模型。结合其强大的推理能力,使模型能够理解真实物理世界。
- 指向能力:Gemini 3 Pro 能够通过输出像素级坐标指向图像中的具体位置,并可以将一系列二维点组合起来执行复杂任务,例如估计人体姿态或随时间推断运动轨迹。
- 开放词汇参考:Gemini 3 Pro 能够利用开放词汇识别对象以及其意图。其中最直接的应用是机器人领域:用户可以要求机器人生成具有空间语义规划的指令,例如“看着这张凌乱的桌子,制定一个分类垃圾的计划”。这种能力同样适用于 AR/XR 设备,例如用户可以请求 AI 助手“根据使用手册指向这个螺丝”。
屏幕理解
Gemini 3 Pro 在空间理解方面的优势在屏幕理解上表现得尤为突出,能够准确解析桌面和移动操作系统的界面。这种可靠性使得计算机使用型智能体足够稳健,可自动化处理重复性任务。界面理解能力还可以支持诸如质量保证(QA)测试、用户引导和用户体验(UX)分析等任务。下面的计算机使用演示展示了模型能够高精度地感知界面并执行点击操作。
,时长00:45
视频理解
Gemini 3 Pro 对视频理解方面实现了巨大飞跃,包括以下三个方面:
- 高帧率理解:模型在 >1 帧/秒 的采样下,对高速动作的理解能力大幅提升。Gemini 3 Pro 能捕捉快速细节:这对分析高尔夫挥杆动作等任务至关重要。
- “思考”模式下的视频推理:升级了“思考”模式,使其不仅限于对象识别,而是迈向真正的视频推理。模型现在能够更好地追踪复杂的因果关系。它不仅能识别事件发生了什么,还能理解事件发生的原因。
- 将长视频转化为行动:Gemini 3 Pro 弥合了视频与代码之间的鸿沟。它可以从长视频内容中提取知识,并立即将其转化为可运行的应用或结构化代码。
真实应用场景
Gemini 3 Pro 可以应用在教育、医疗、法律和金融等真实场景。首先,Gemini 3 Pro 增强的视觉能力在教育领域带来了显著提升,尤其适用于以图表为主的数学和科学问题。它能够成功应对从初中到高等教育课程中出现的全方位多模态推理问题。这包括视觉推理题(如 Math Kangaroo)以及复杂的化学和物理图表。Gemini 3 的视觉智能也为 Nano Banana Pro 的生成能力提供了支持。通过将高级推理与精确生成相结合,模型能够帮助用户准确找出作业题中出错的环节。

其次,Gemini 3 Pro 也是在医疗与生物医学影像理解方面能力最强的通用模型,在主要公开基准测试中表现出色,包括 MedXpertQA-MM(一个高难度的专家级医学推理考试)、VQA-RAD(放射影像问答)以及 MicroVQA(基于显微镜的生物研究多模态推理基准)。
最后,Gemini 3 Pro 增强的文档理解能力帮助金融和法律领域的专业人士应对高度复杂的工作流程。金融平台可以无缝分析充满图表和表格的密集报告,而法律平台则能从模型先进的文档推理能力中获益。

这里补充一点,Gemini 3 Pro 在处理视觉输入时,通过保持图像的原始纵横比来提升处理效果,从而在整体上显著提高了图像质量。此外,开发者可以通过新增的 media_resolution 参数对性能和成本进行精细控制。这使得可以根据视觉 token 的使用情况,在画质与资源消耗之间进行平衡:
- 高分辨率:最大化细节保真度,适用于需要精细信息的任务,例如密集 OCR 或复杂文档理解。
- 低分辨率:优化成本和延迟,适用于较简单的任务,例如一般场景识别或长上下文处理任务。
本文内容仅供参考,不构成任何专业建议。使用本文提供的信息时,请自行判断并承担相应风险。